文章摘要
文章探讨了图书馆和数字人文项目在数据发现服务中面临的成本与可访问性平衡问题,指出传统方法需要昂贵的服务器和数据库支持。作者介绍了哈佛法学院创新实验室开发的"Data.gov Archive Search"项目,旨在通过新方法降低技术复杂度,同时保持数据检索功能。
文章总结
重新思考图书馆与数字人文领域的数据发现方式 | 图书馆创新实验室

(图片来源:维基共享资源)
{kind=link}
作为公共数据项目的一部分,哈佛法学院图书馆创新实验室(LIL)近期推出了Data.gov档案搜索平台。本文深入探讨了该项目的构建逻辑与技术实现。
传统困境:成本、复杂性与可访问性的权衡
图书馆、数字人文项目和文化遗产机构长期面临在线共享馆藏时的两难选择:
- 动态服务模式:需部署服务器和数据库以支持浏览、筛选和搜索功能,但高昂的运维成本(安全更新、技术维护)和人员依赖易导致项目因预算或人事变动而停滞。
- 静态托管模式:如Amazon S3存储每月成本可低至1美元,但用户仅能通过预渲染的脆弱层级结构访问数据,客户端内存限制也严重制约搜索体验。
为何探索新路径?
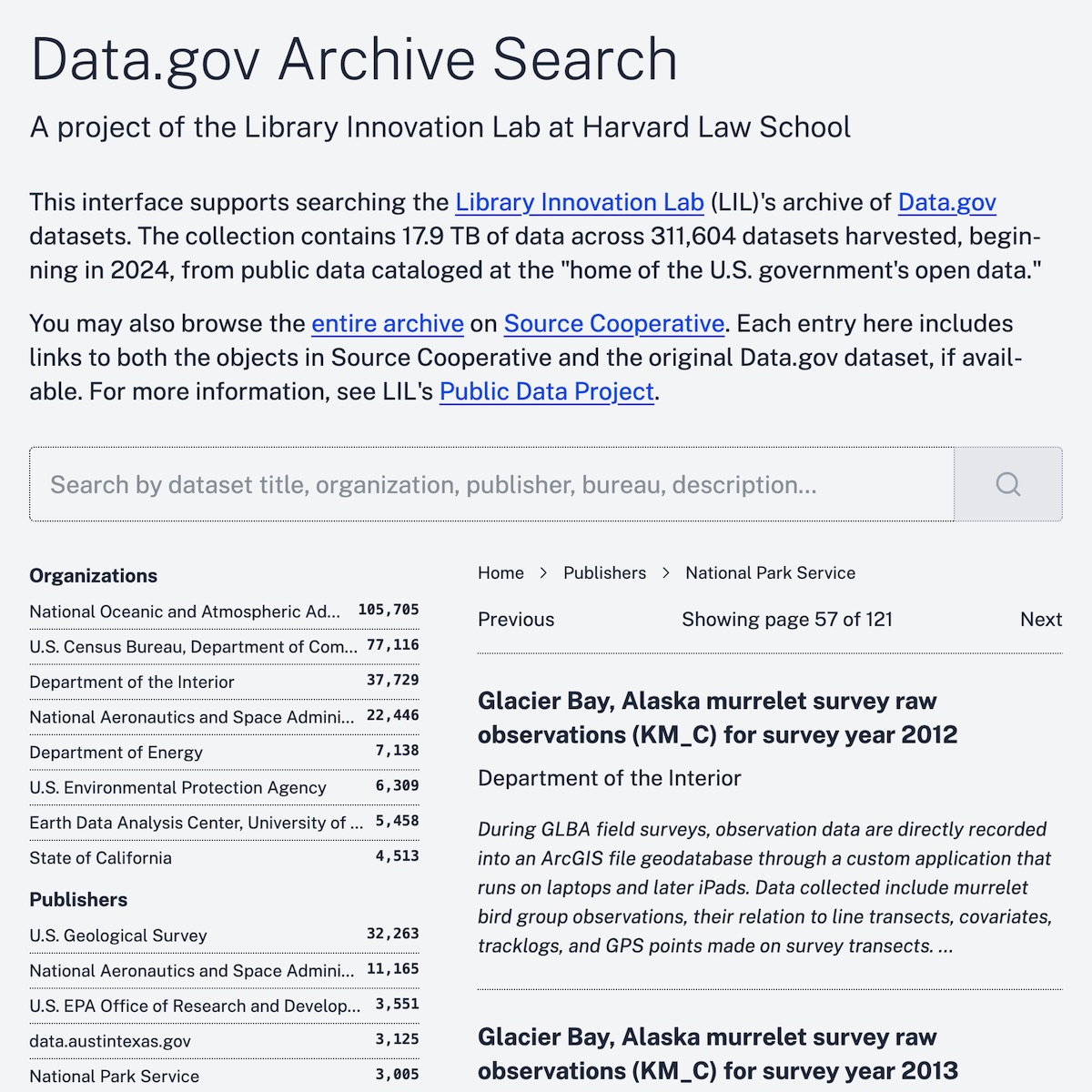
在构建Data.gov档案库(18TB数据,1GB元数据)的发现系统时,LIL团队确立了核心目标:
1. 轻量化维护:避免重蹈"案例法访问项目"(CAP)因11TB数据迁移而被迫转为静态站点的覆辙。
2. 可持续访问:确保长期可用性,同时降低资源消耗。
技术实验:无服务器的动态发现方案
借助WebAssembly等前沿技术,团队开发了基于浏览器端的解决方案:
- 数据存储:元数据以压缩Parquet格式存放于静态托管平台Source.coop。
- 查询引擎:通过DuckDB-Wasm在用户浏览器内实现完整的数据库功能。
- 按需加载:仅提取查询所需数据片段,避免全量下载(如2GB文件的局部检索)。
当前挑战:
- DuckDB-Wasm初始加载延迟较高,团队正测试Hyparquet、Arquero等替代方案以优化性能。
行业意义:普惠型数据发现的新范式
该模式为各类知识机构提供三重价值:
1. 成本控制:静态存储显著降低运营开支。
2. 技术减负:无需后端服务器,彻底规避安全补丁和崩溃风险。
3. 持久性:系统在人员更迭后仍可持续运行。
行动建议:
- 对拥有静态数据集的组织,可尝试浏览器端搜索工具原型。
- 鼓励社区共享模板应用与经验,推动技术模式成熟。
LIL将持续开源工具代码,欢迎图书馆与数字文化遗产领域同仁通过lil@law.harvard.edu参与协作。
(注:原文发表于2025年10月31日,部分技术细节可能已迭代更新。)
评论总结
以下是评论内容的总结:
对DuckDB-Wasm技术组合的赞赏
- 认为S3廉价存储+DuckDB+WASM的组合实现了无后端查询,令人惊叹
- "Put all of that together...with no backend at all. Amazing"
- "It's one of the best tricks in the book...bring real time system observability"
关于技术实现的疑问
- 询问是否支持其他存储后端如RocksDB
- 对DDOS防护的担忧:"how one stops ddos. Put the whole thing behind Cloudflare?"
- 质疑浏览器处理大数据量的必要性:"why query 1TB of data in a browser"
使用体验的负面反馈
- 内存管理和线程配置困难导致频繁崩溃
- "lots of crashes...many OOM out of memory errors"
- "Life is too short for crashy database software"
成功应用案例
- 有开发者成功将类似技术用于产品开发
- "We have been doing it...bring real time system observability"
- 个人项目中使用DuckDB处理数据:"DuckDB is phenomenal tech...love to use it with data ponds"
与其他技术的比较
- 团队更信任Postgres而放弃DuckDB方案
- "They wanted to trust Postgres"
- 提到类似技术方案:"Yesterday there was a somewhat similar DuckDB post"
性能与适用场景讨论
- 既肯定其大数据处理能力:"very capable of large sets"
- 也质疑浏览器场景的适用性:"pushing that everything has to be in a browser"