文章摘要
Vectroid是一款无服务器向量搜索解决方案,旨在以低成本提供高准确性和低延迟。现有向量数据库在速度、准确性和成本之间往往需要做出妥协,而Vectroid通过重新设计底层机制,成功实现了高效、准确且经济的搜索性能,适用于各种场景。
文章总结
为什么我们构建了Vectroid
我们很高兴宣布推出Vectroid,这是一款无服务器向量搜索解决方案,能够在低成本的前提下提供卓越的准确性和低延迟。Vectroid不仅仅是一个普通的向量搜索工具,它是一个在各种场景下都能高效运行和扩展的搜索引擎。
构建Vectroid的原因
与任何处理大规模、低延迟向量工作负载的团队交流,你都会听到一个熟悉的故事:总有一些方面需要妥协。向量数据库通常在速度、准确性和成本之间做出重大权衡。这是向量搜索数学基础的本质——通过算法“捷径”在短时间内获得近乎完美的结果。
这些权衡通常表现为以下几种形式:
- 非常高的准确性,但非常昂贵且速度慢
- 速度快且准确性可接受,但非常昂贵
- 便宜且速度快,但准确性低到无法接受的程度
基于现有的向量数据库现状,似乎构建一个成本效益高的向量数据库需要在大规模下牺牲速度或准确性。我们认为这是一个错误的假设:构建一个高准确性、低延迟且成本效益高的数据库是可能的。我们只需要重新思考底层机制。
我们的“顿悟”时刻
查询速度和召回率很大程度上取决于所选的近似最近邻(ANN)算法。像HNSW(分层可导航小世界)这样既快速又准确的算法,内存密集且索引成本高。传统假设认为这些类型的算法对于成本敏感的系统是不可行的。
我们有两个重要的发现挑战了这一假设:
- 对内存中HNSW的需求不是静态的。 实际使用模式是突发且不均匀的。一个成本效益高的数据库可以通过动态分配资源和根据需要单独扩展系统组件来优化这一现实。
- HNSW的内存占用是可调的。 它可以轻松地被压缩(例如通过量化压缩向量)或扩展(例如通过增加层数),这为我们提供了灵活性,可以尝试不同的配置以找到最佳设置。
什么是Vectroid?
Vectroid是一款无服务器向量数据库,具有卓越的性能。它提供了与高端产品相同或更强的速度和召回率平衡,但成本低于竞争对手。
- 高性能向量搜索:使用HNSW进行超快速、高召回率的相似性搜索。
- 近实时搜索能力:新摄入的记录几乎可以立即搜索。
- 大规模扩展性:无缝处理单个命名空间中的数十亿个向量。
- 成本效益高的资源利用:分别扩展每一层(摄入、索引、查询)。
Vectroid的表现如何
Vectroid的核心理念是,不惜一切代价优化一个指标并不能构建一个稳健的系统。相反,向量搜索应该设计为在召回率、延迟和成本之间实现平衡性能,这样用户就不必在工作负载增长时做出痛苦的权衡。
在与其他最先进的向量搜索进行测试时,Vectroid不仅具有竞争力,而且在各个方面表现最为一致。在所有测试中,Vectroid是唯一能够在扩展到每秒10个查询线程的同时保持超过90%召回率并保持良好延迟得分的数据库。
一些早期基准测试:
- 在约48分钟内索引了10亿个向量(Deep1B)
- 在MS Marco 138M向量/1024维数据集上实现了34ms的P99延迟
我们将在即将发布的文章中发布完整的基准测试套件(包括设置细节,以便任何人都可以复现)。目前,这些数字突显了我们设计Vectroid以处理的规模和性能。
Vectroid的工作原理
Vectroid由两个独立可扩展的微服务组成,分别用于写入和读取。
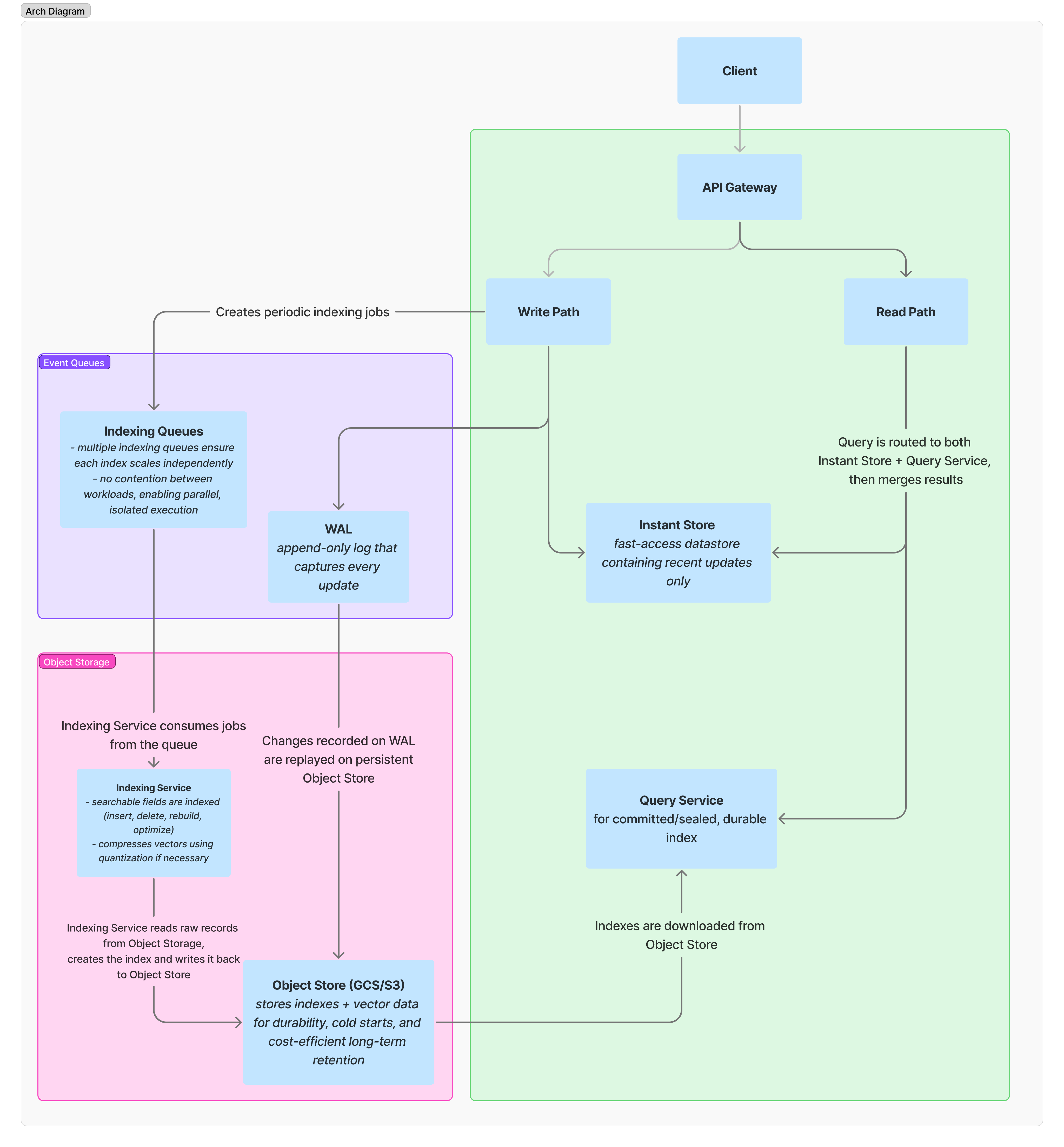
如图所示,索引状态、向量数据和元数据持久化到云对象存储(目前是GCS,即将支持S3)。磁盘、缓存和内存存储层各自采用使用感知模型进行索引生命周期管理,其中索引在需要时从对象存储中懒加载,并在空闲时被驱逐。
为了实现快速、高召回率的ANN搜索,我们选择了HNSW算法。它提供了出色的延迟和准确性权衡,支持增量更新,并在大规模工作负载下表现良好。为了弥补其局限性,我们添加了一些有针对性的优化:
- 索引速度慢 ⇒ 内存写入缓冲区,确保新插入的向量可以立即搜索
- 索引成本高 ⇒ 批量、高度并发和分区的索引
- 内存使用率高 ⇒ 通过量化进行向量压缩
最后的话
我们才刚刚开始。如果你正在构建依赖快速、可扩展向量搜索的应用程序(或者你正在遇到当前堆栈的极限),我们很乐意听取你的意见。立即开始使用Vectroid,或注册我们的新闻通讯,以继续关注我们的构建过程。
评论总结
对技术实现的质疑:
- 评论2指出该技术是“专有闭源锁定”,认为没有太多值得关注的地方。
引用:Proprietary closed-source lock-in. Nothing to see here. - 评论7询问该技术与在Elasticsearch上运行调优的HNSW向量索引有何不同。
引用:How is this different from running tuned HNSW vector indices on Elasticsearch?
- 评论2指出该技术是“专有闭源锁定”,认为没有太多值得关注的地方。
对技术差异的探讨:
- 评论3提出疑问,询问该技术与TurboPuffer等基于无服务器对象存储的向量数据库有何区别。
引用:How is this different from TurboPuffer and other serverless, object storage backed vector databases? - 评论9呼吁开发一个独立的“向量引擎”库,以便不同系统可以轻松集成,而不必每次都重新发明核心向量功能。
引用:I would like to see a “DataFusion for Vector databases,” i.e. an embeddable library that Does One Thing Well.
- 评论3提出疑问,询问该技术与TurboPuffer等基于无服务器对象存储的向量数据库有何区别。
对实际应用场景的讨论:
- 评论6认为10亿向量并不需要索引,可以在单个节点的VRAM中运行查询,且毫秒级响应。
引用:1B vectors is nothing. You can hold them in VRAM on a single node and run queries with perfect accuracy in milliseconds. - 评论8引用论文,质疑10亿向量的实用性,指出高维向量的准确性在文档数量达到一定规模时会下降。
引用:They show that with 4096-dimensional vectors, accuracy starts to fail at 250 mln documents.
- 评论6认为10亿向量并不需要索引,可以在单个节点的VRAM中运行查询,且毫秒级响应。
对技术复杂性的批评:
- 评论10认为向量数据库领域存在误解,指出大多数公司并不需要处理数十亿的嵌入,并推荐使用SQLite扩展进行优化暴力搜索。
引用:It’s crazy how people add bloat and complexity to their stuff just because they want to do medium scale RAG with ca. 2 million embeddings. 引用:I stumbled over https://github.com/sqliteai/sqlite-vector which is a SQLite extension and I wonder why no one else did this before.
- 评论10认为向量数据库领域存在误解,指出大多数公司并不需要处理数十亿的嵌入,并推荐使用SQLite扩展进行优化暴力搜索。
对硬件和背景的关注:
- 评论4对基准测试的硬件设置表示好奇。
引用:Very curious about the hardware setup used for this benchmark! - 评论5提到该技术的创建者曾开发实时数据平台Hazelcast。
引用:By the creator of the real-time data platform https://en.wikipedia.org/wiki/Hazelcast.
- 评论4对基准测试的硬件设置表示好奇。