文章摘要
文章探讨了AI模型的普适性,认为所有AI模型可能本质上相同,并提到如果AI能学习一种通用语言,或许能用于与鲸鱼交流。文章还通过一个猜词游戏“墨索里尼还是面包”来类比不同事物在概念空间中的距离,暗示AI模型在处理信息时可能具有相似的逻辑框架。
文章总结
文章主要内容总结:
标题:所有AI模型可能都是一样的
核心观点: 随着AI模型的规模不断扩大,它们逐渐趋同,学习到相似的表示方式,这种现象被称为“柏拉图表示假设”(Platonic Representation Hypothesis)。文章通过多个角度探讨了这一假设,并提出了其在实际应用中的潜力。
模型趋同的现象:
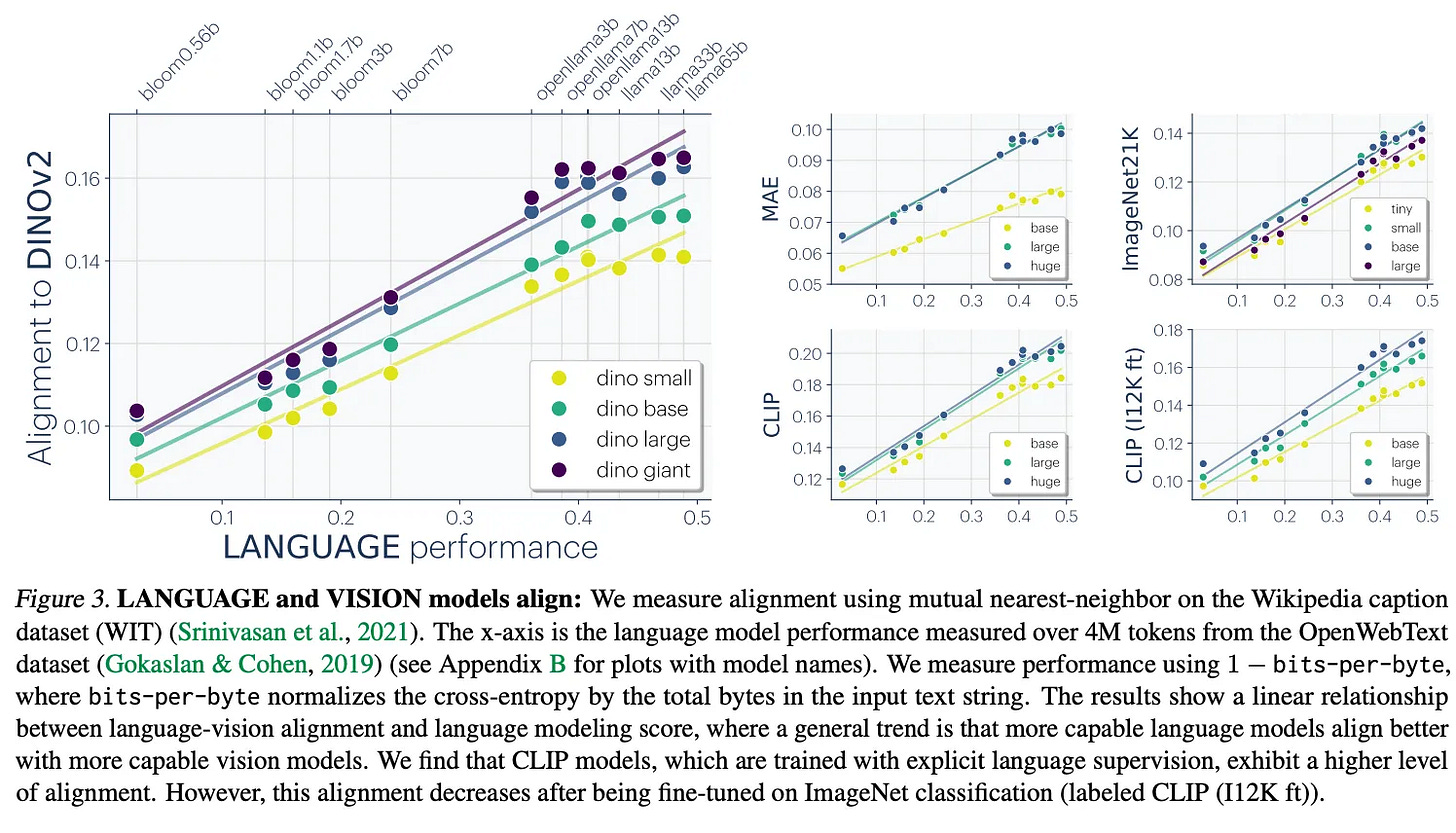
- 随着模型规模的增大,它们学习到的特征越来越相似。这种现象在文本和语言模型中尤为明显。
- 柏拉图表示假设认为,模型正在收敛到一个共享的表示空间,且随着模型变得更大、更智能,这种趋同性会进一步增强。
压缩与智能的关系:
- 智能可以被视为一种压缩过程。通过压缩数据,模型能够更好地理解世界。
- 研究表明,更智能的语言模型在压缩数据方面表现更好,压缩与智能之间存在对偶关系。
模型的泛化与压缩:
- 当模型无法完全拟合训练数据时,它被迫将多个数据点的信息结合起来,从而实现泛化。
- 泛化通常以相同的方式发生,即使是在不同的模型中。这是因为在给定的架构和参数数量下,只有一种最佳的数据压缩方式。
嵌入反演问题:
- 嵌入反演是指从神经网络的表示向量中推断出输入文本的过程。尽管嵌入向量高度压缩,但通过迭代优化,可以实现高精度的反演。
- 基于柏拉图表示假设,研究者开发了一种通用的嵌入反演方法,能够在不同模型之间进行无监督的转换。
跨模型的表示对齐:
- 通过类似CycleGAN的方法,研究者成功实现了不同模型嵌入空间之间的无监督对齐,进一步验证了柏拉图表示假设。
- 这种方法不仅适用于文本模型,还可以应用于图像-文本嵌入模型(如CLIP)。
机制解释性与通用特征:
- 在机制解释性研究中,不同模型表现出相似的功能和特征,进一步支持了模型趋同的观点。
- 稀疏自编码器(SAEs)的研究表明,不同模型学习到的特征存在大量重叠。
实际应用与未来展望:
- 柏拉图表示假设不仅在哲学上有重要意义,还具有实际应用价值,如解码古代文字(如线性文字A)或实现跨物种的语音转换(如鲸鱼语音)。
- 随着模型规模的进一步扩大,模型之间的相似性将更加显著,这为未来的研究和应用提供了新的方向。
图片标记:
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
- 
评论总结
关于Transformer模型的局限性
- 评论1指出,AGI(通用人工智能)不会基于Transformer模型,暗示Transformer可能存在局限性。
- 引用:“When we arrive at AGI, you can be certain it will not contain a Transformer.”
- 评论12提到,许多独立开发的AI模型在回答问题时表现出相似的措辞,暗示模型之间的趋同性。
- 引用:“many of the large, separately developed AIs often answer with remarkably similar wording to the same question.”
语义模型与知识匹配的挑战
- 评论2认为,语义模型的有效性依赖于知识水平的匹配,专家与专家、通才与通才之间的互动更有效。
- 引用:“The solution is to match knowledge levels: experts play with experts, generalists with generalists.”
- 评论8指出,缺乏共享经验背景的语言(如鲸语或古代语言)难以被解码,强调了上下文的重要性。
- 引用:“Context is the most important part of what makes language useful.”
模型压缩与效率问题
- 评论3提出,如果模型在表示上趋同,是否可以构建更高效的架构以实现压缩。
- 引用:“If models converge on similar representations, we should be able to build more efficient architectures around those core features.”
- 评论5提到,尽管存在通用的计算方法,但并非所有模型在效率上都是等同的,实际应用中仍面临挑战。
- 引用:“Not all models are equally efficient.”
AI模型的趋同性与开放性
- 评论13认为,所有AI模型可能在本质上趋同,因为它们都基于人类的集体智慧。
- 引用:“All AI models might be the same.”
- 评论18提出,如果模型趋同,开源模型将使得专有模型变得过时,支持开源的重要性。
- 引用:“If they all converge to the same intelligence, one open source model would make all proprietary models obsolete.”
AI模型的局限性与改进方向
- 评论10通过实际案例指出,领域特定的AI模型虽然有用,但仍需要高效的“事实检查”系统来避免错误。
- 引用:“I am sure that domain specific LLMs are where it is at but we need some sort of efficient ‘fact checker’ system.”
- 评论15建议,AI需要实时感官输入和模拟激素等机制,以更接近人类大脑的创造力。
- 引用:“What we need to do is provide AIs with realtime sensory input, simulated hormones each with their own half-lifes.”
总结:评论围绕AI模型的趋同性、效率、语义理解及局限性展开讨论,支持开源模型的重要性,并提出了改进AI模型的潜在方向。