文章摘要
2025年7月14日,Cloudflare的1.1.1.1解析服务在全球范围内出现了中断,持续时间为UTC时间21:52至22:54。此次中断导致大部分用户无法使用该服务,进而影响了互联网的正常访问。中断原因是由于维护基础设施的旧系统配置错误,导致Cloudflare的IP地址无法正确广播到互联网。Cloudflare对此表示歉意,并强调此次中断并非由攻击或BGP劫持引起,而是内部配置错误所致。公司正在采取措施确保类似事件不再发生。
文章总结
文章主要内容总结:
标题:Cloudflare 1.1.1.1 服务在2025年7月14日的中断事件
发布时间:2025年7月15日
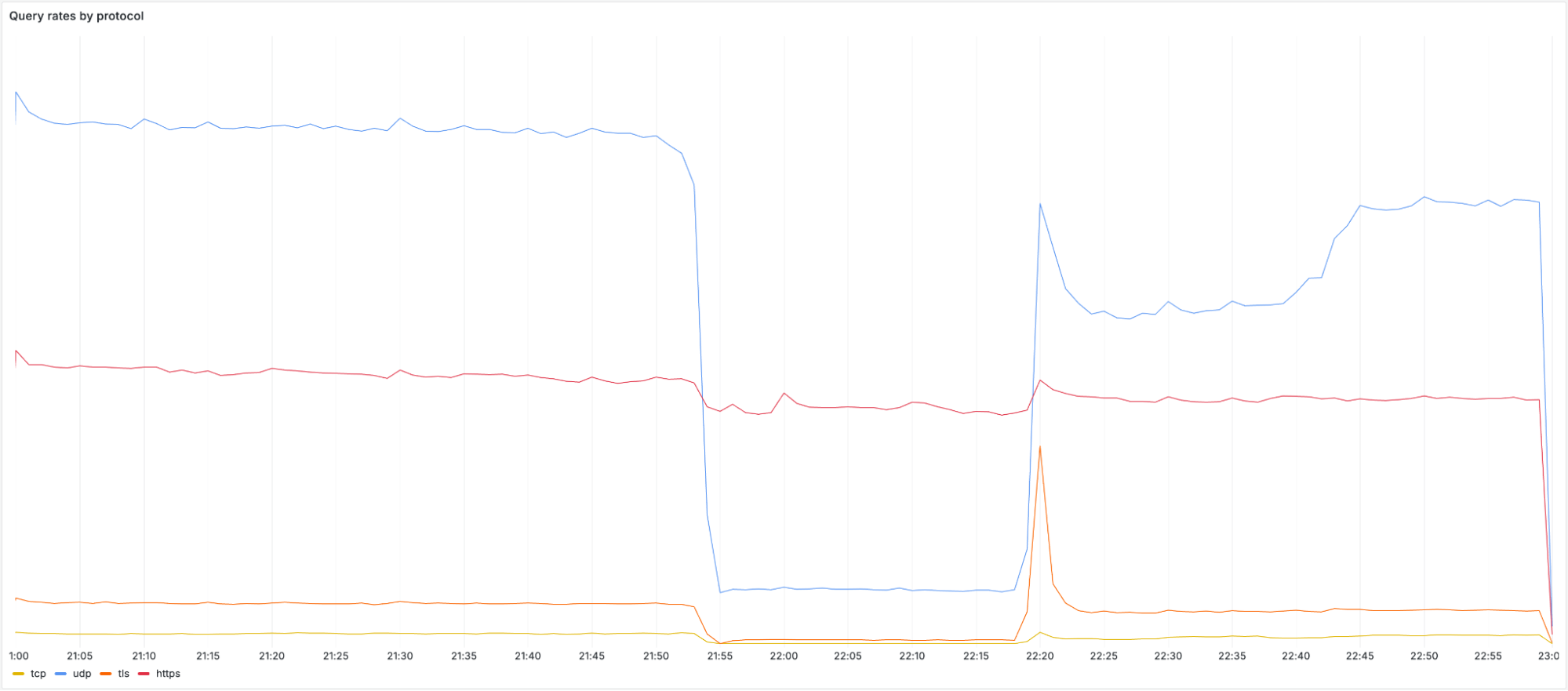
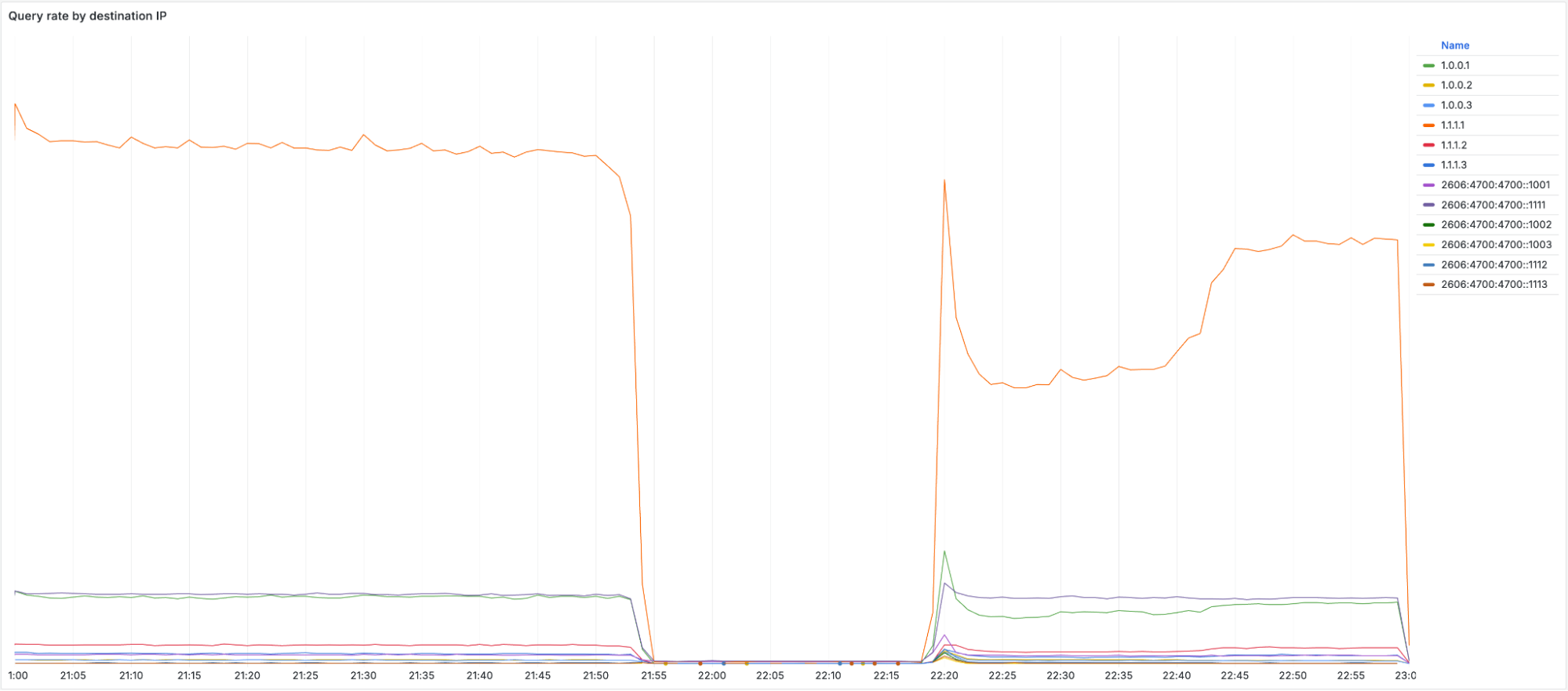
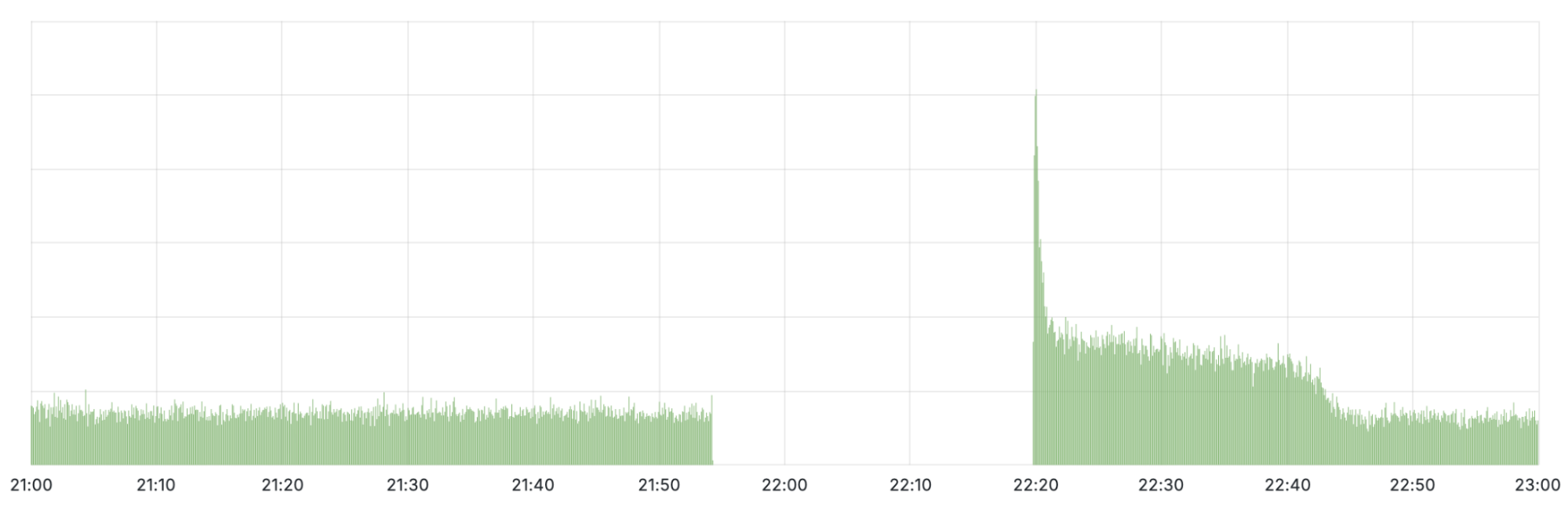
事件概述: 2025年7月14日,Cloudflare的1.1.1.1 DNS解析服务在全球范围内中断,从UTC时间21:52开始,持续到22:54。此次中断影响了全球大部分使用1.1.1.1的用户,导致他们无法解析域名,进而无法访问互联网服务。中断的原因是用于维护基础设施的遗留系统配置错误,导致Cloudflare的IP地址无法正确通告到互联网。
背景: Cloudflare于2018年推出了1.1.1.1公共DNS解析服务,采用Anycast技术实现全球流量管理。然而,Anycast的全球性也意味着一旦IP地址的通告出现问题,可能导致全球性中断。6月6日,在为未来的数据本地化套件(DLS)服务准备拓扑结构时,配置错误被引入,导致1.1.1.1的IP地址被错误地关联到非生产服务中。这一错误在7月14日的配置变更中被触发,导致1.1.1.1的IP地址从全球Cloudflare数据中心中撤回。
事件时间线: - 2025-06-06 17:38:配置错误被引入,但未立即影响生产网络。 - 2025-07-14 21:48:配置变更触发全局网络配置刷新,1.1.1.1的IP地址被撤回。 - 2025-07-14 21:52:1.1.1.1解析服务开始全球中断。 - 2025-07-14 22:01:内部警报触发,事件被正式宣布。 - 2025-07-14 22:20:修复部署,恢复之前的配置。 - 2025-07-14 22:54:服务恢复正常,事件解决。
影响:
中断期间,所有通过1.1.1.1解析服务的流量都受到影响,包括UDP、TCP和DNS over TLS(DoT)流量。然而,DNS over HTTPS(DoH)流量相对稳定,因为大多数DoH用户通过域名cloudflare-dns.com访问服务,而非直接使用IP地址。
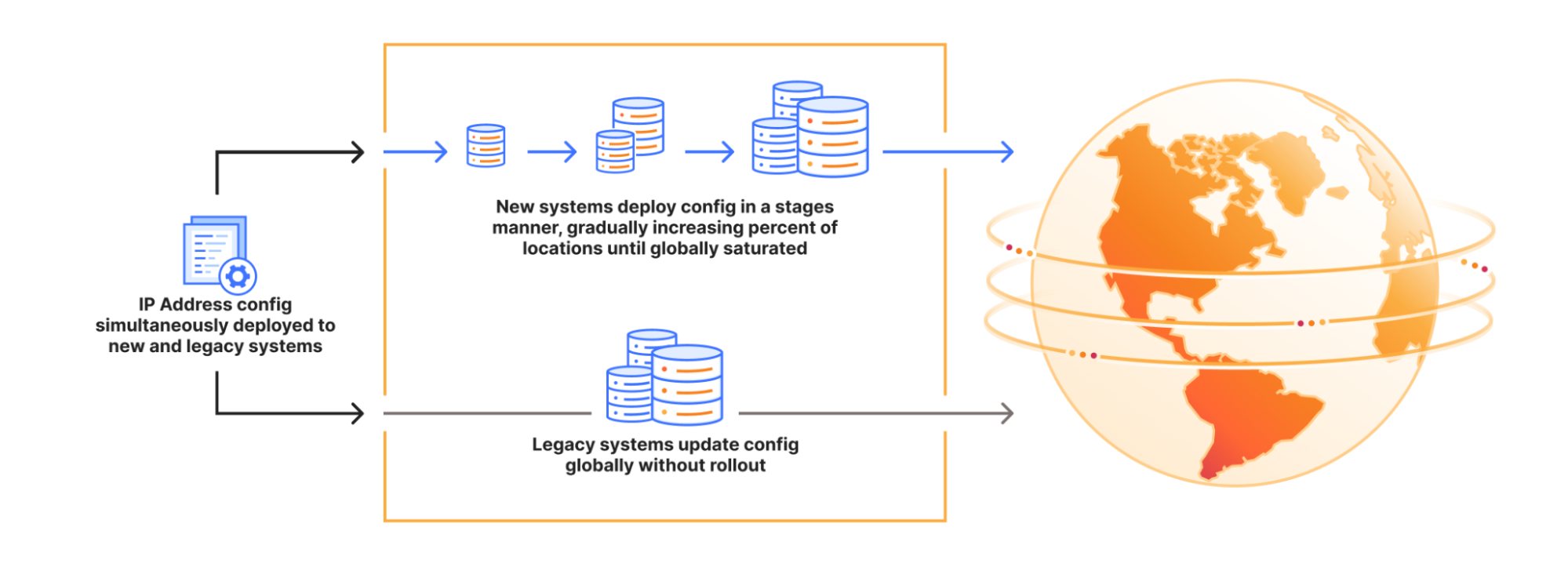
技术分析: 中断的根本原因是遗留系统和现代系统之间的同步问题。Cloudflare目前使用两种系统来管理服务拓扑结构,遗留系统依赖于硬编码的数据中心列表,容易出错。现代系统则采用更灵活的部署模型,允许逐步部署和健康监控。此次事件暴露了在迁移过程中同时维护两种系统的风险。
修复措施: Cloudflare在22:20 UTC恢复了之前的配置,并重新通告了撤回的BGP前缀。然而,部分边缘服务器需要重新配置IP绑定,导致服务恢复时间延长。最终,服务在22:54 UTC完全恢复。
未来改进: 为了防止类似事件再次发生,Cloudflare计划: 1. 逐步部署:淘汰遗留系统,采用现代逐步部署和健康监控流程。 2. 加速淘汰遗留系统:减少遗留系统的使用,提高文档和测试覆盖率。
结论: Cloudflare对此次中断事件表示歉意,并承诺通过技术改进确保未来服务的稳定性。


评论总结
主要观点总结:
DNS服务中断的影响与恢复
- 评论1提到,尽管发生了中断,但DoH(DNS-over-HTTPS)流量相对稳定,因为大多数用户通过域名访问Cloudflare的DNS解析器,而不是直接通过IP地址。
- 引用:"Interesting that traffic didn't return to completely normal levels after the incident."
- 引用:"I recently started using the 'luci-app-https-dns-proxy' package on OpenWrt... since DoH was mostly unaffected, I didn't notice an outage."
- 评论4指出,即使路由器启用了Cloudflare DoH,仍然无法解析域名,切换到Google DNS(8.8.8.8)后问题解决。
- 引用:"My router (supposedly) had Cloudflare DoH enabled but nothing would resolve. Changing the DNS server to 8.8.8.8 fixed the issues."
- 评论1提到,尽管发生了中断,但DoH(DNS-over-HTTPS)流量相对稳定,因为大多数用户通过域名访问Cloudflare的DNS解析器,而不是直接通过IP地址。
DNS备份与故障转移
- 评论2和评论8讨论了使用多个DNS提供商作为备份的重要性,建议使用Google DNS(8.8.8.8)或Quad9(9.9.9.9)作为备用。
- 引用:"It's crazy that both 1.1.1.1 and 1.0.0.1 were affected by the same change. Maybe 8.8.8.8 or 9.9.9.9."
- 引用:"Perhaps I'll switch back to using 8.8.8.8 as secondary... it is failover not round-robin between the primary and secondary DNS servers."
- 评论12强调DNS应具备故障容错能力,建议确保主备DNS服务完全独立。
- 引用:"The whole point is that it can go down at any time and everything keeps working. Shouldn’t the fix be to ensure that these are served out of completely independent silos?"
- 评论2和评论8讨论了使用多个DNS提供商作为备份的重要性,建议使用Google DNS(8.8.8.8)或Quad9(9.9.9.9)作为备用。
Cloudflare与Google DNS的稳定性对比
- 评论5和评论8对Cloudflare(1.1.1.1)和Google DNS(8.8.8.8)的稳定性进行了比较,认为Cloudflare的故障报告更多,但响应速度更快。
- 引用:"I wonder how uptime ratio of 1.1.1.1 is against 8.8.8.8. Maybe there is noticeable difference?"
- 引用:"Cloudflare on aggregate was quicker to respond to queries and changed everything to use 1.1.1.1 and 1.0.0.1."
- 评论5和评论8对Cloudflare(1.1.1.1)和Google DNS(8.8.8.8)的稳定性进行了比较,认为Cloudflare的故障报告更多,但响应速度更快。
配置错误与监控问题
- 评论9和评论11对Cloudflare的配置错误和监控延迟表示惊讶,认为如此极端的流量下降应在更短时间内被检测到。
- 引用:"I’m surprised at the delay in impact detection: it took their internal health service more than five minutes to notice."
- 引用:"A test triggered a global production change? You have a process that allows some other service to just hoover up address routes already in use in production by a different service?"
- 评论9和评论11对Cloudflare的配置错误和监控延迟表示惊讶,认为如此极端的流量下降应在更短时间内被检测到。
总结:
评论主要围绕Cloudflare DNS服务中断的影响、DNS备份的重要性、Cloudflare与Google DNS的稳定性对比,以及配置错误和监控问题展开。用户普遍认为应使用多个DNS提供商作为备份,并对Cloudflare的故障处理流程提出了质疑。