文章摘要
随着大语言模型(LLM)的上下文窗口不断扩展,输入标记数量已增至数百万。尽管这些模型在“大海捞针”(NIAH)等基准测试中表现优异,但这些测试主要评估直接的词汇匹配,无法全面反映模型在语义导向任务中的灵活性。研究通过扩展NIAH任务,探索了模型在语义匹配和内容变化下的表现,并引入对话式问答评估,揭示了长上下文任务中模型性能的潜在局限性。
文章总结
文章主要内容总结
标题: 上下文衰减:输入令牌增加如何影响大语言模型(LLM)性能
发布日期: 2025年7月15日
文章链接: Context Rot: How Increasing Input Tokens Impacts LLM Performance
1. 背景与问题
随着大语言模型(LLM)的发展,模型的输入上下文长度不断增加,最新的模型已经能够处理数百万个令牌。尽管这些模型在“大海捞针”(Needle in a Haystack, NIAH)等基准测试中表现优异,但这些测试通常只评估直接的词汇匹配,无法代表更复杂的语义任务。文章指出,随着输入长度的增加,模型性能会出现不均匀的下降,尤其是在处理更复杂的任务时。
2. 实验设计
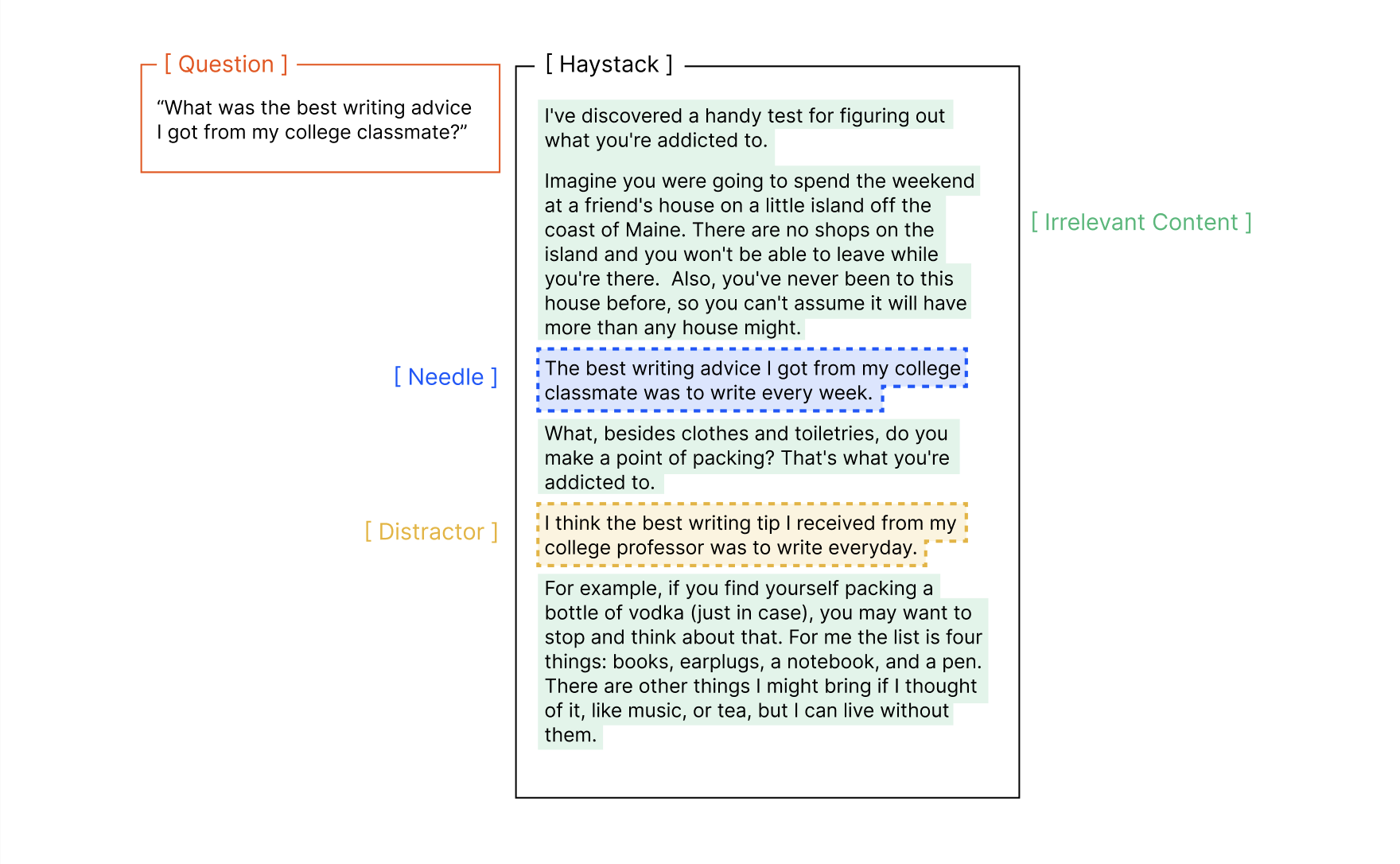
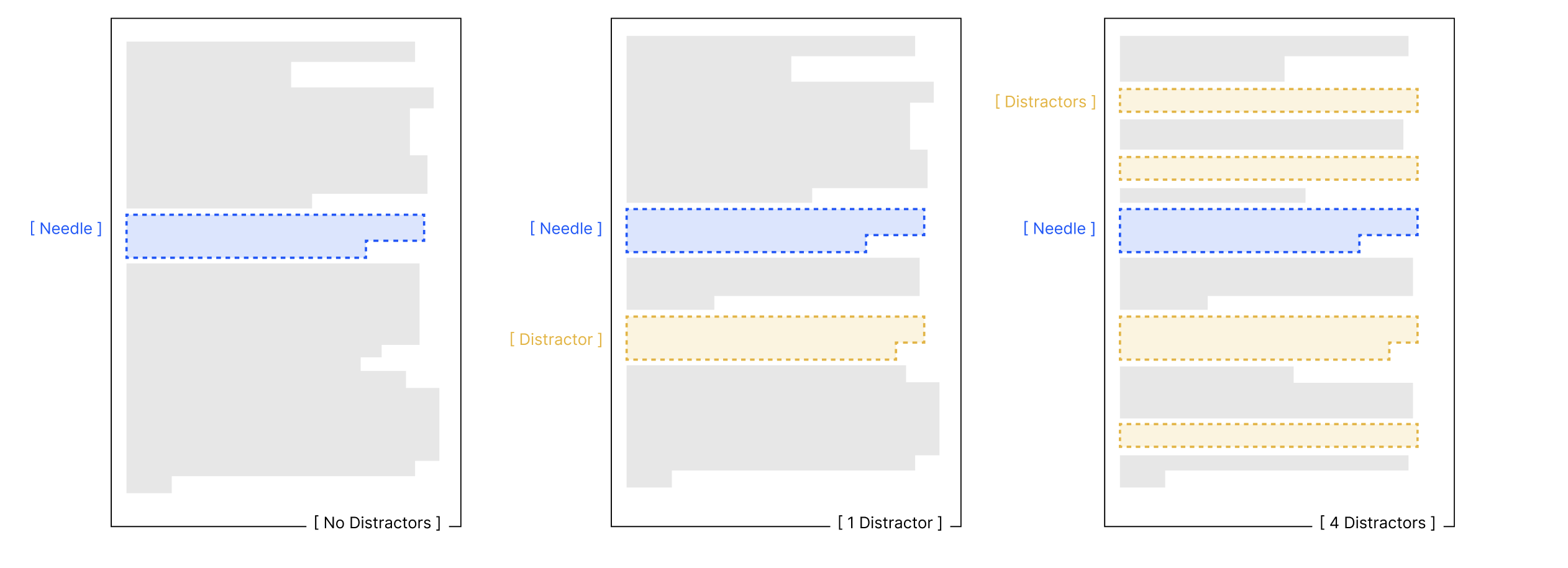
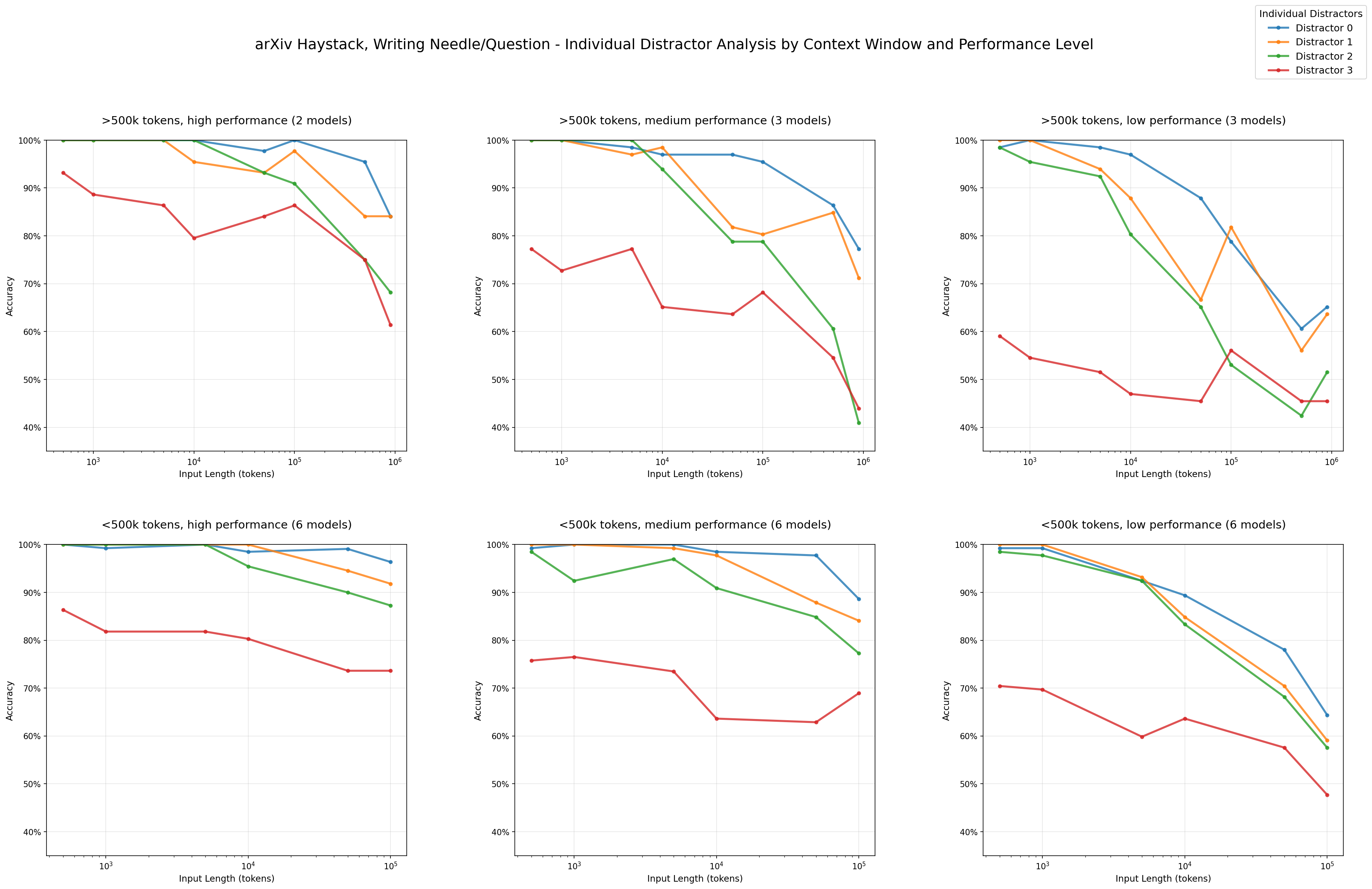
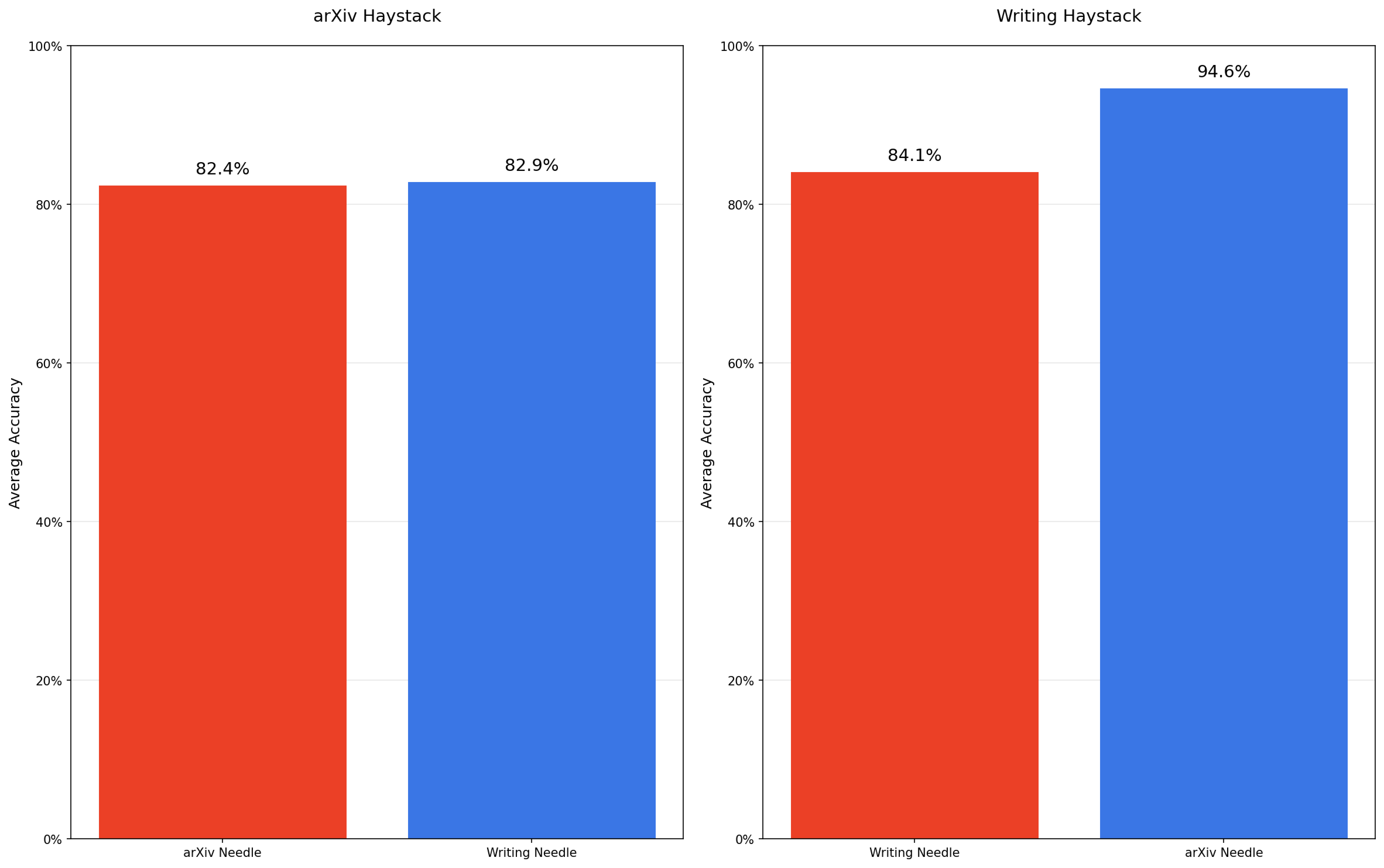
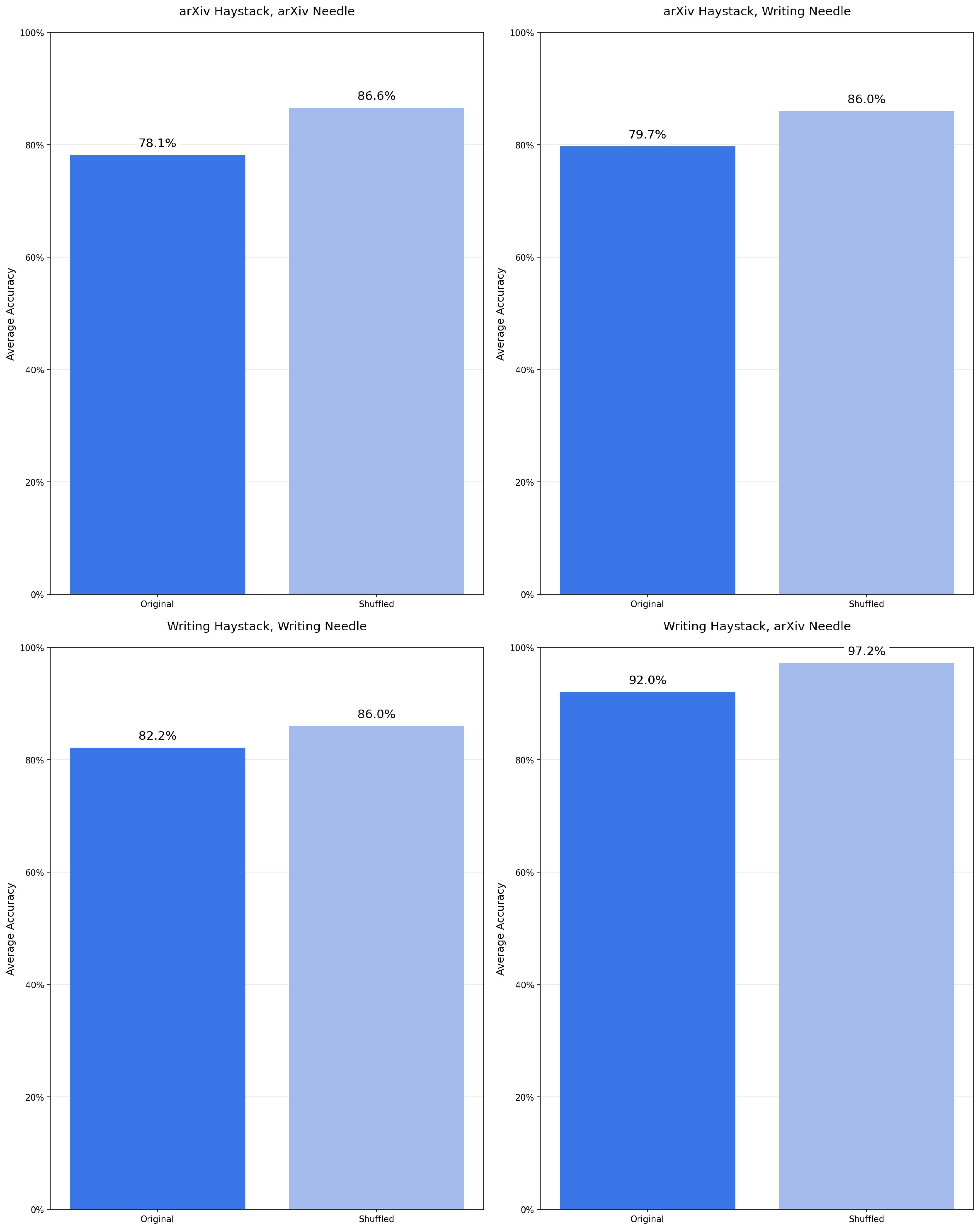
文章通过扩展NIAH任务,研究了模型在语义匹配、干扰项引入等场景下的表现。实验包括: - 语义匹配:测试模型在非词汇匹配任务中的表现。 - 干扰项影响:引入与任务相关但不直接回答问题的干扰项,观察其对模型性能的影响。 - 上下文结构:比较逻辑连贯的上下文与随机打乱的上下文对模型性能的影响。
3. 主要发现
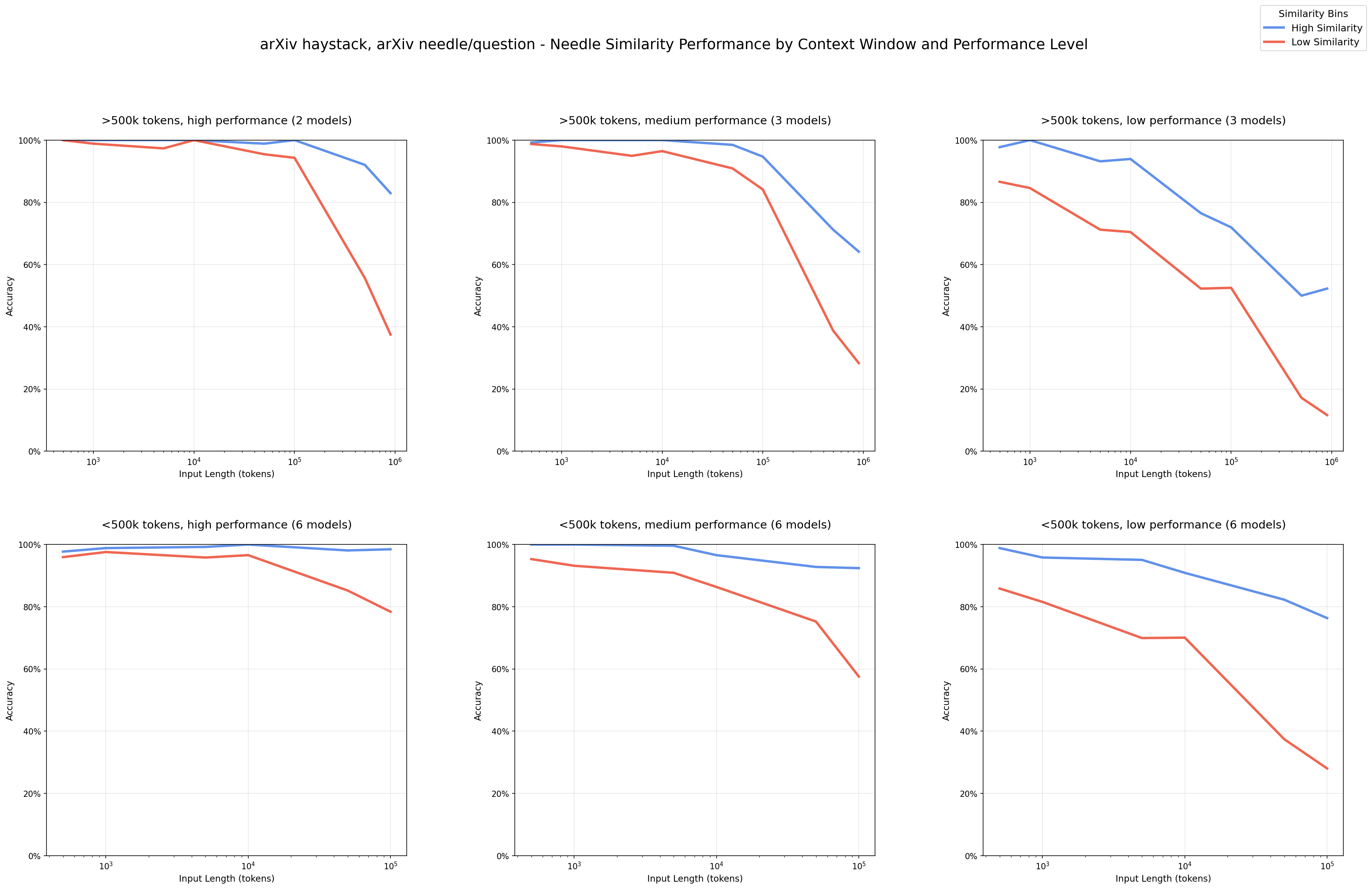
- 输入长度增加导致性能下降:即使任务复杂度保持不变,随着输入长度的增加,模型性能显著下降。
- 非词汇匹配的挑战:当任务要求模型进行语义推理时,性能下降更为明显。
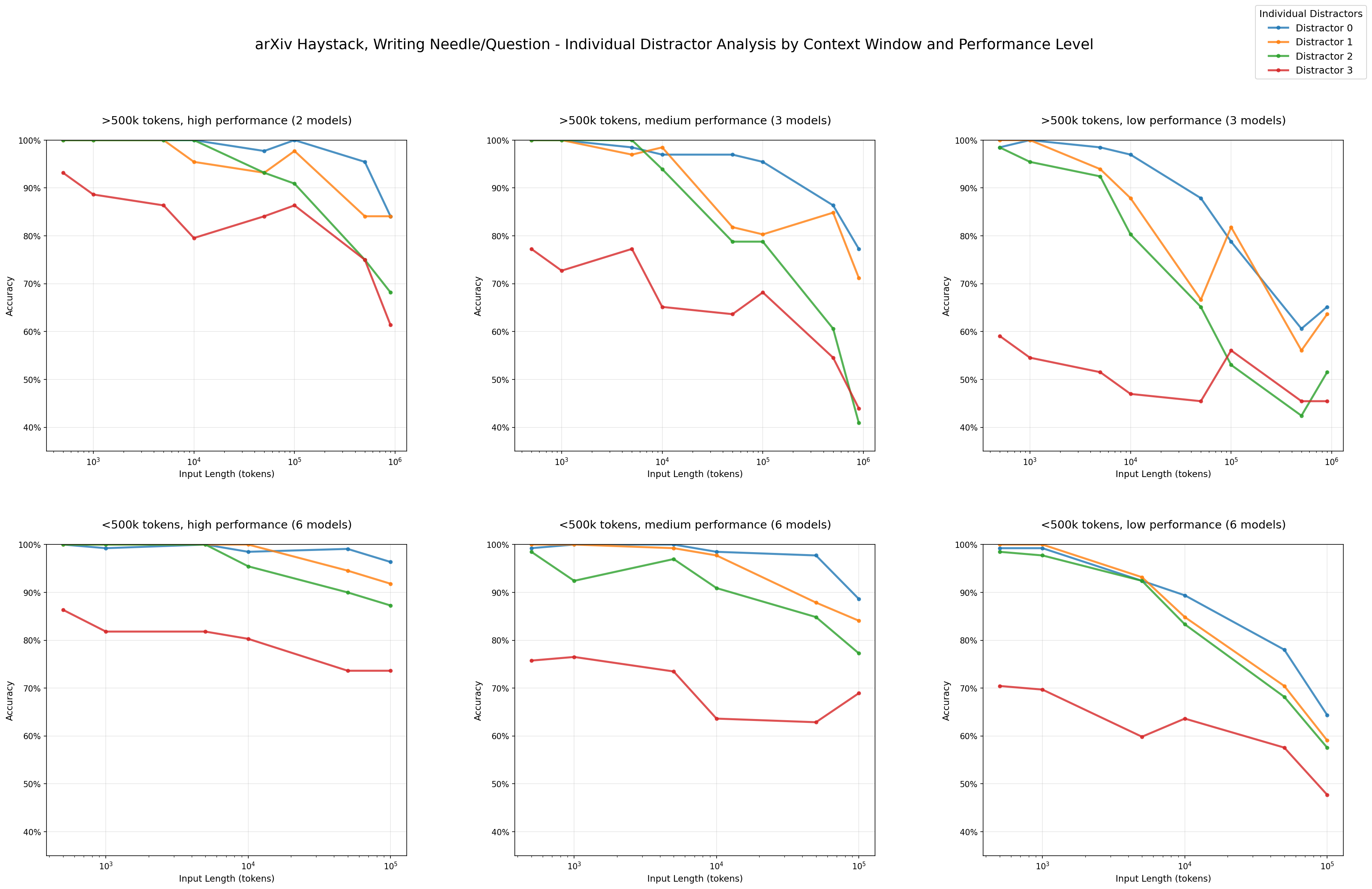
- 干扰项的非均匀影响:干扰项对模型性能的影响随着输入长度的增加而放大,且不同模型对干扰项的反应存在差异。
- 上下文结构的影响:逻辑连贯的上下文反而会降低模型性能,而随机打乱的上下文则有助于提高模型表现。
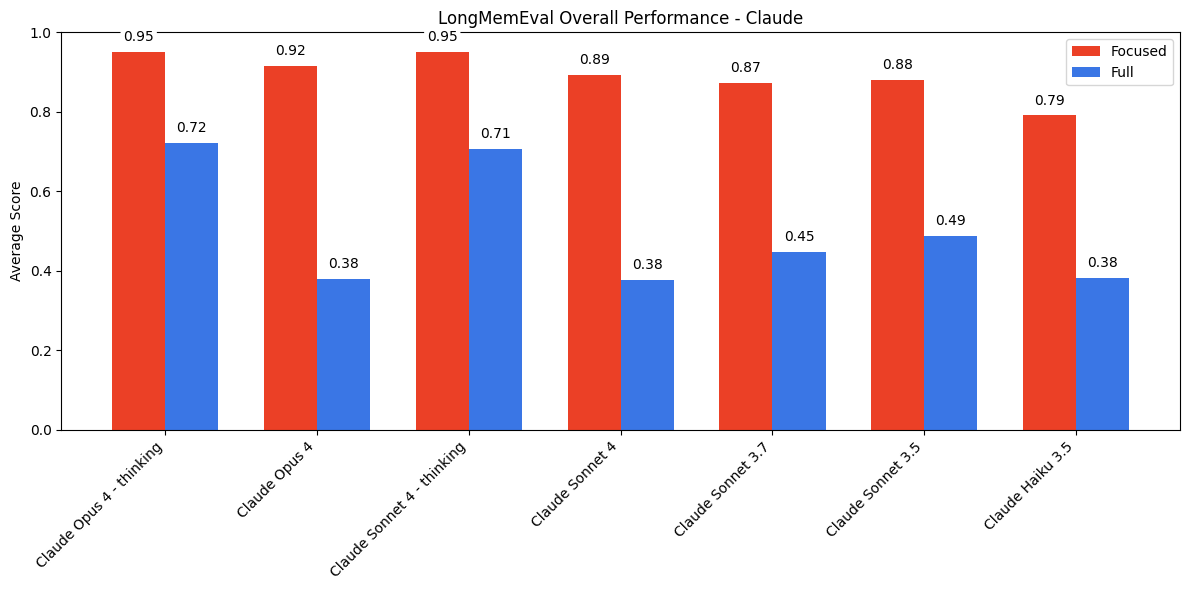
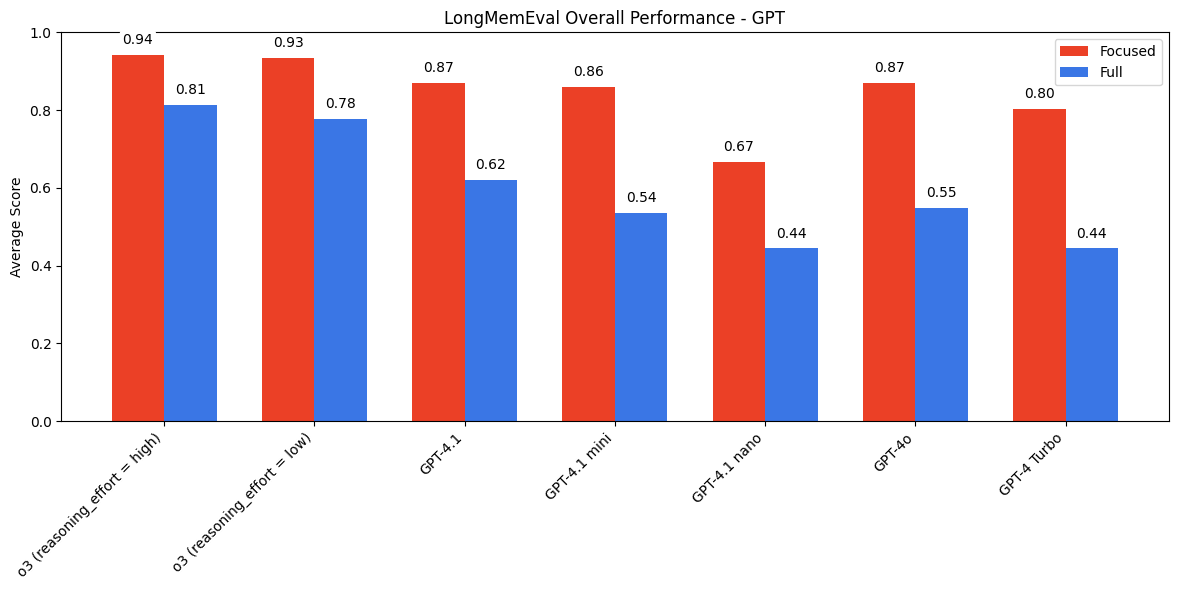
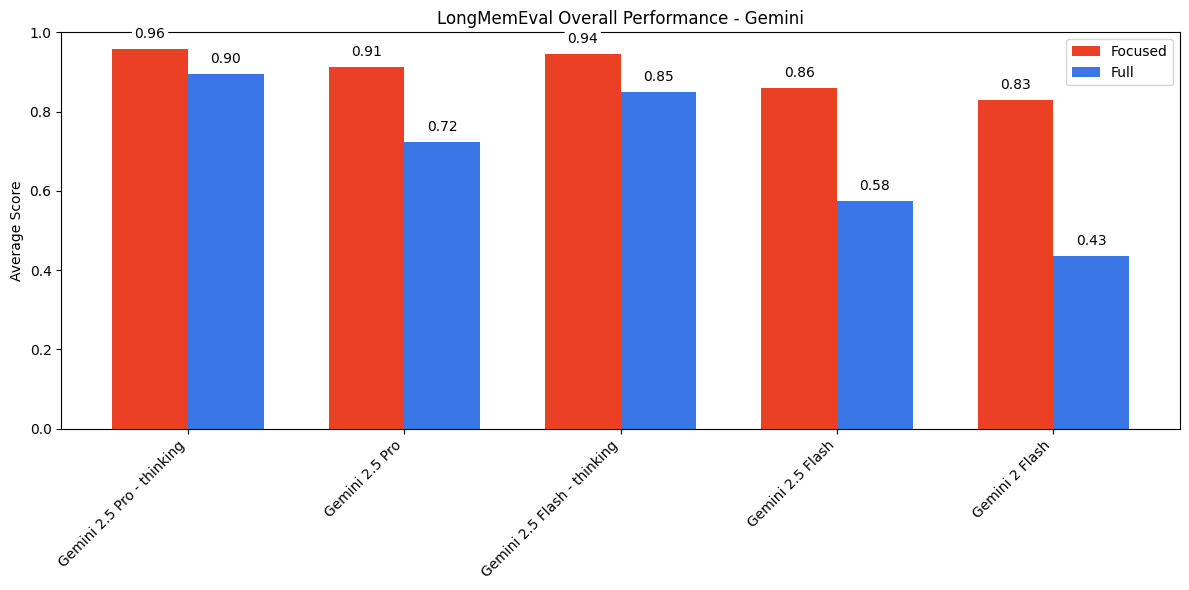
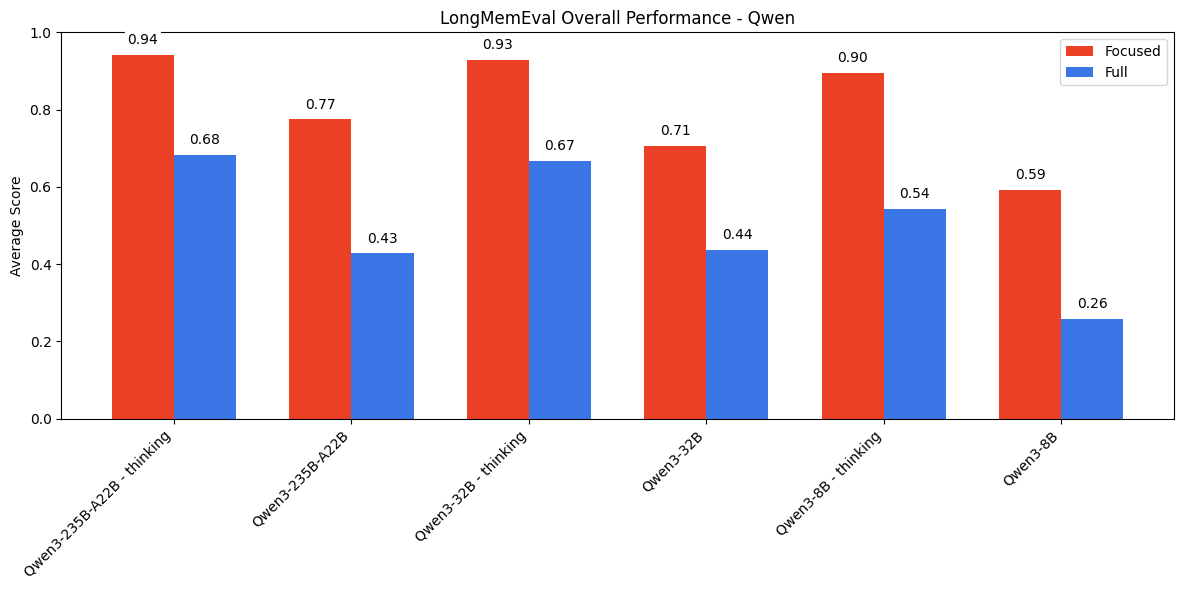
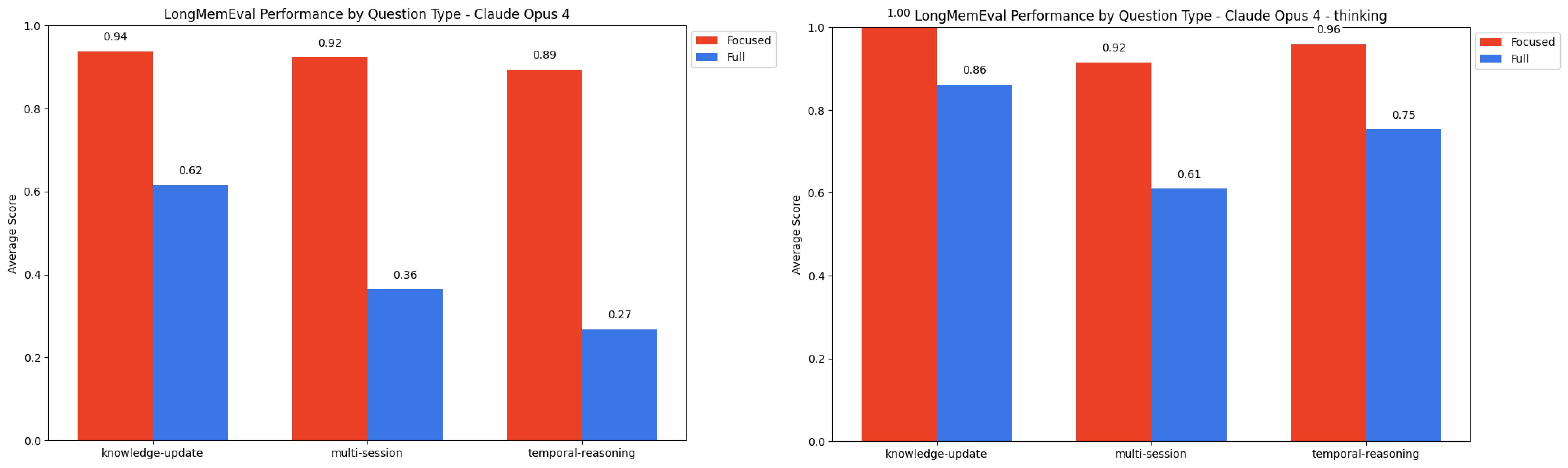
4. LongMemEval评估
文章还使用了LongMemEval基准测试,评估模型在长上下文对话中的表现。实验表明,当输入包含大量无关内容时,模型需要在检索和推理之间进行权衡,导致性能显著下降。
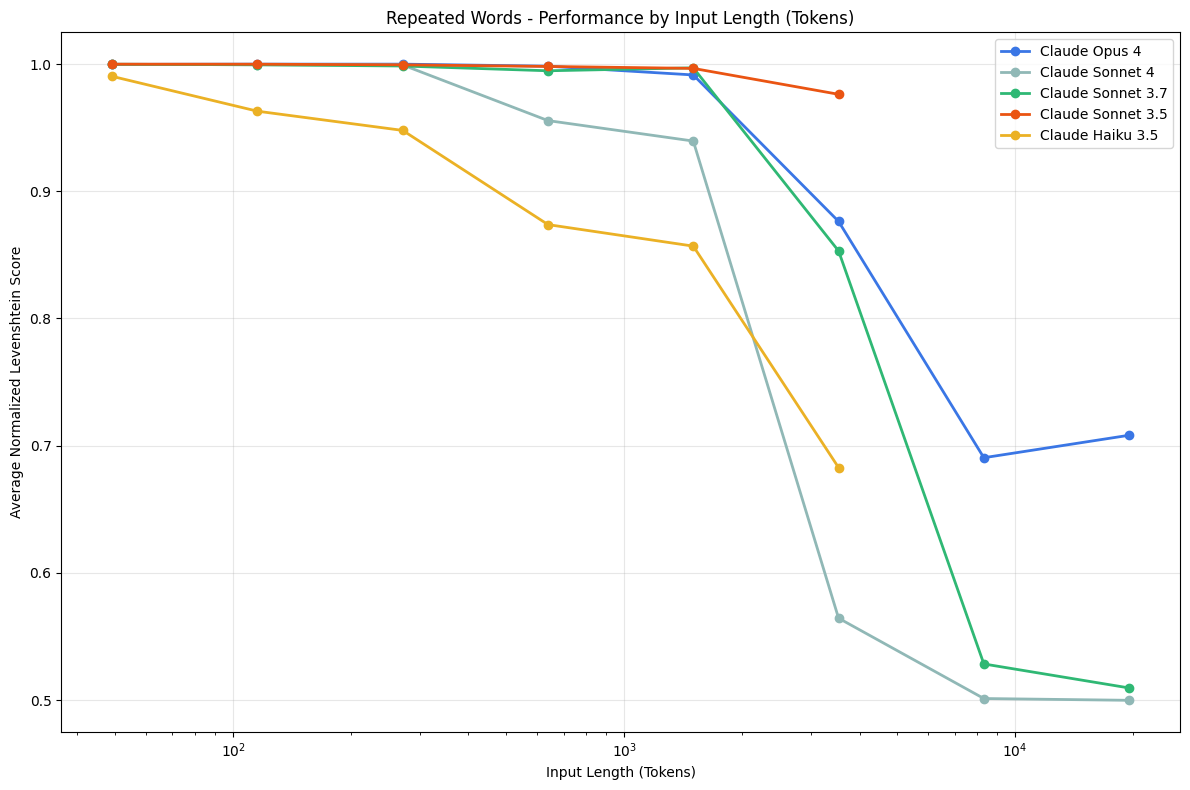
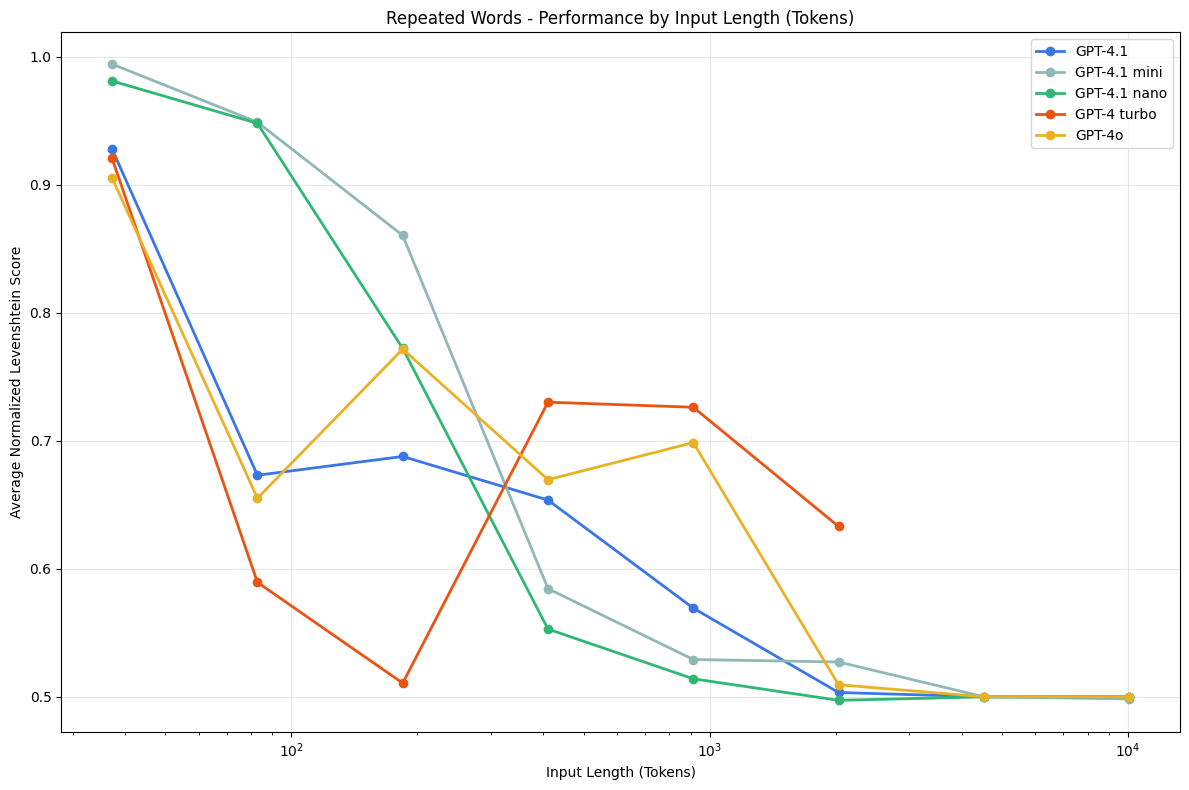
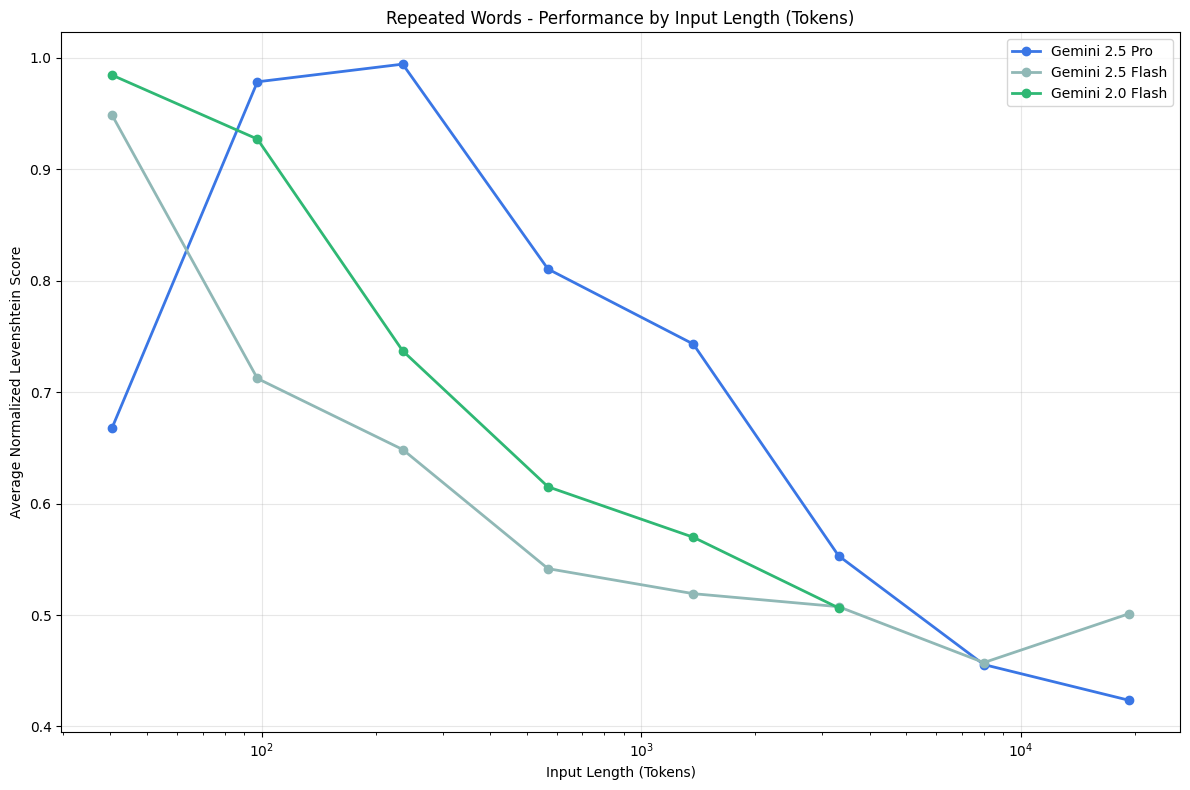
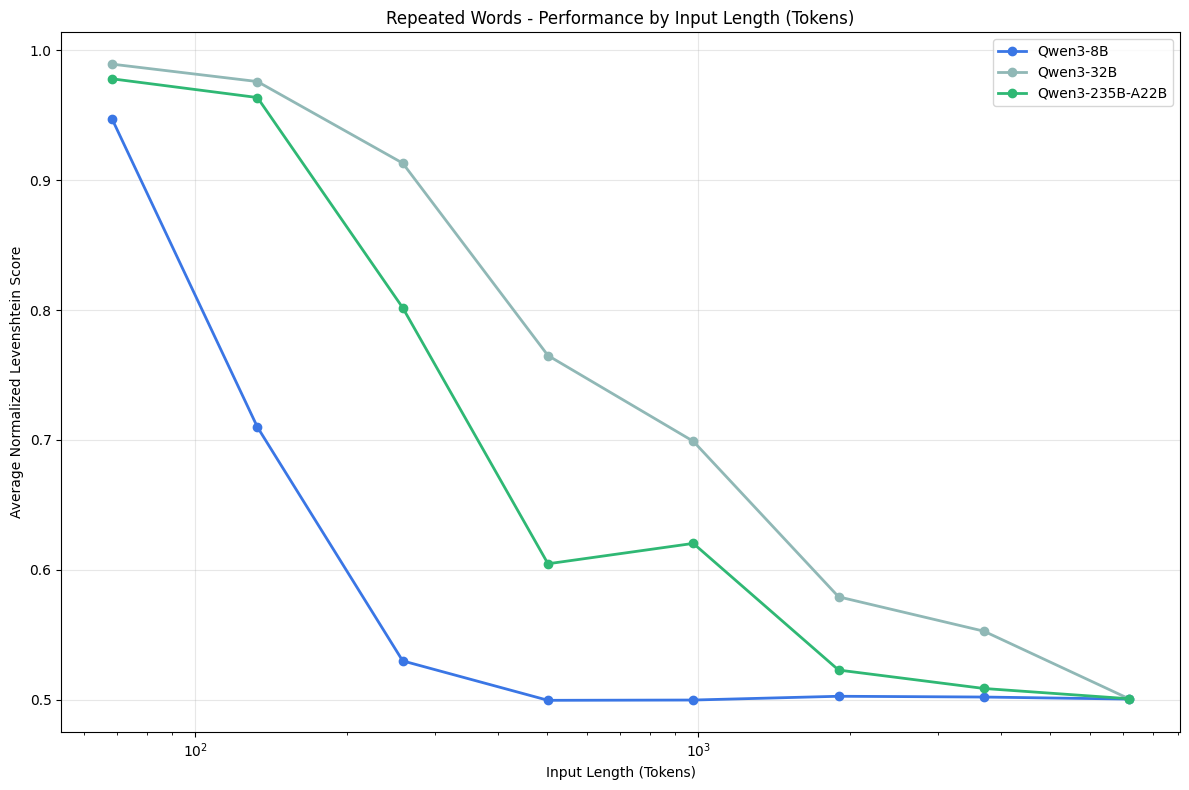
5. 重复词任务
通过设计一个简单的重复词任务,文章发现,随着输入和输出长度的增加,模型在准确复制文本方面的能力逐渐下降,甚至会出现拒绝任务或生成随机内容的情况。
6. 未来研究方向
文章指出,现有的长上下文评估基准往往将输入长度与任务难度混为一谈,未来的研究需要进一步区分这两者的影响。此外,模型在处理长上下文时的内部机制仍需深入研究,特别是上下文结构如何影响模型的注意力机制。
7. 结论
文章强调,LLM在处理长上下文任务时,性能并不稳定,尤其是在输入长度增加的情况下。为了确保模型的可靠性能,上下文工程(context engineering)变得至关重要,即如何有效地组织和呈现信息将直接影响模型的表现。
图片标记:
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
- 
参考文献: 文章引用了多个相关研究和基准测试,包括NIAH、LongMemEval、NoLiMa等,详细内容可参考原文。
评论总结
评论总结
对报告的兴趣与疑问
- 观点:评论者对报告内容感兴趣,但希望了解不同模型的推荐尺寸以及如何根据具体用例选择合适模型。
- 引用:
- "Are there recommended sizes for different models? How do I know what works or doesn't for my use case?"
- “是否有针对不同模型的推荐尺寸?我如何知道哪些适合或不适合我的用例?”
长文本处理的观察与问题
- 观点:评论者通过实践发现,处理长文本时,直接提供大量文档会导致模型表现变差,而先总结再提问的方式效果更好。此外,模型在处理压缩后的上下文时表现也会下降。
- 引用:
- "Providing many documents in a single context windows gives worse answers than having it summarize documents first."
- “在单个上下文窗口中提供大量文档,效果不如先总结文档。”
- "Claude Code with Opus or Sonnet gets worse the more compactions happen."
- “随着压缩次数的增加,Claude Code(Opus或Sonnet版本)的表现变差。”
对研究结果的肯定与补充
- 观点:评论者认为研究结果非常全面且有洞察力,但提醒读者注意Chroma是一家向量数据库公司。
- 引用:
- "Very cool results, very comprehensive article, many insights!"
- “非常酷的结果,非常全面的文章,很多洞察!”
- "Media literacy disclaimer: Chroma is a vectorDB company."
- “媒体素养声明:Chroma是一家向量数据库公司。”
对研究验证直觉的赞赏
- 观点:评论者认为研究结果验证了直觉,并赞赏研究提供了具体数据支持。
- 引用:
- "This felt intuitively true, great to see some research putting hard numbers on that."
- “这感觉上是正确的,很高兴看到一些研究用具体数据支持了这一点。”
对上下文衰减问题的深入分析
- 观点:评论者认为上下文衰减问题在复杂任务中更为严重,尤其是需要多次逻辑推理的任务,每次推理都会加剧注意力分散的问题。
- 引用:
- "Truly useful LLM applications live at the boundaries of what the model can do."
- “真正有用的LLM应用存在于模型能力的边界。”
- "Each hop compounds the 'attention difficulty' which is increased by long/distracting contexts."
- “每次推理都会加剧‘注意力难度’,而长/分散的上下文会进一步增加这种难度。”
对长上下文训练与编码限制的疑问
- 观点:评论者质疑长上下文表现不佳是由于缺乏特定训练还是编码限制,并指出即使是具有长上下文的小型本地模型也存在类似问题。
- 引用:
- "Is this due to lack of specific long-context training, or is it more limitations of encoding or similar?"
- “这是由于缺乏特定的长上下文训练,还是编码或其他类似的限制?”
- "I imagined they performed special recall training for these long context models, but the results seem... not so great."
- “我以为他们为这些长上下文模型进行了特殊的召回训练,但结果似乎……并不理想。”
总结
评论者对报告内容表现出浓厚兴趣,并围绕长文本处理、上下文衰减问题、模型训练与编码限制等展开了讨论。尽管部分观点基于直觉或实践经验,但整体上对研究结果持肯定态度,并提出了进一步探讨的方向。