文章摘要
Apache Parquet文件不仅支持基本的Min/Max/Null Count统计和Bloom过滤器,还可以在不改变规范或创建新文件格式的情况下,通过页脚元数据和基于偏移量的寻址嵌入用户自定义的索引结构。这种灵活性使得在查询时能够更高效地剪裁文件,例如通过存储列中所有不同值的列表来跳过不相关的文件,从而提升查询性能,同时保持与标准Parquet读取器的完全兼容性。
文章总结
文章主要内容总结
标题: 在 Apache Parquet 文件中嵌入用户自定义索引
发布日期: 2025年7月14日
作者: Qi Zhu, Jigao Luo, Andrew Lamb
文章概述:
本文探讨了如何在 Apache Parquet 文件中嵌入用户自定义索引,而无需修改 Parquet 规范或创建新的文件格式。文章详细介绍了 Parquet 文件的内部结构、标准索引机制,并通过示例展示了如何使用 Apache DataFusion 读写用户自定义索引。
1. 背景与动机
- 常见误解: 许多人认为 Parquet 文件仅支持基本的 Min/Max/Null Count 统计和 Bloom Filter,添加更高级的索引需要修改规范或创建新格式。
- 实际解决方案: Parquet 文件的页脚元数据和基于偏移量的寻址机制已经支持嵌入用户自定义索引,且不会破坏与其他 Parquet 读取器的兼容性。
- 示例: 假设数据中有
Nation列,查询时可以通过嵌入的“唯一值索引”快速跳过不包含目标值的文件,从而显著提高查询性能。
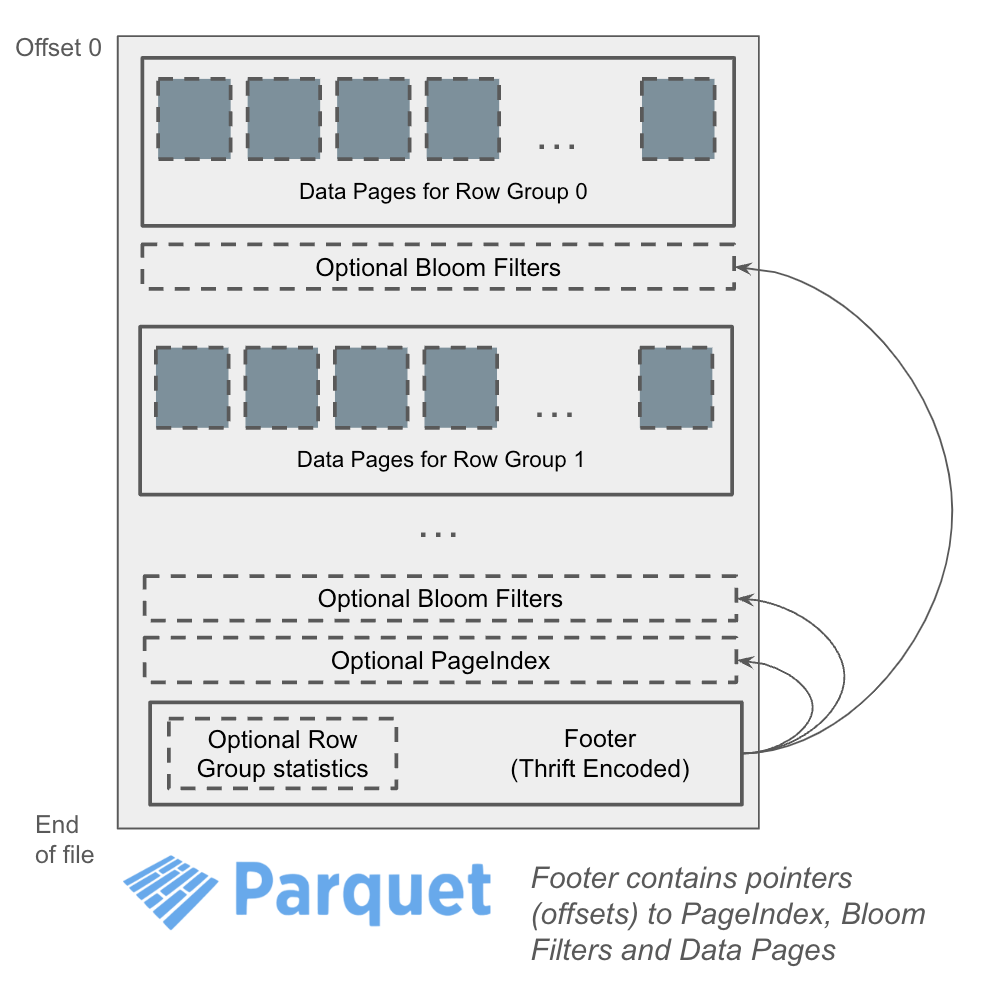
2. Parquet 文件结构与标准索引
- 逻辑结构: Parquet 文件包含行组(Row Group)、列块(Column Chunk)和数据页(Data Page)。
- 物理结构: Parquet 文件是一个字节序列,末尾包含 Thrift 编码的页脚元数据,记录了文件的结构信息。
- 标准索引类型:
- Min/Max/Null Count 统计: 用于快速跳过不符合查询条件的行组。
- 页索引: 记录每个数据页的偏移量和统计信息,用于快速定位数据页。
- Bloom Filter: 用于快速判断某个值是否存在于列块中,特别适用于等值查询。
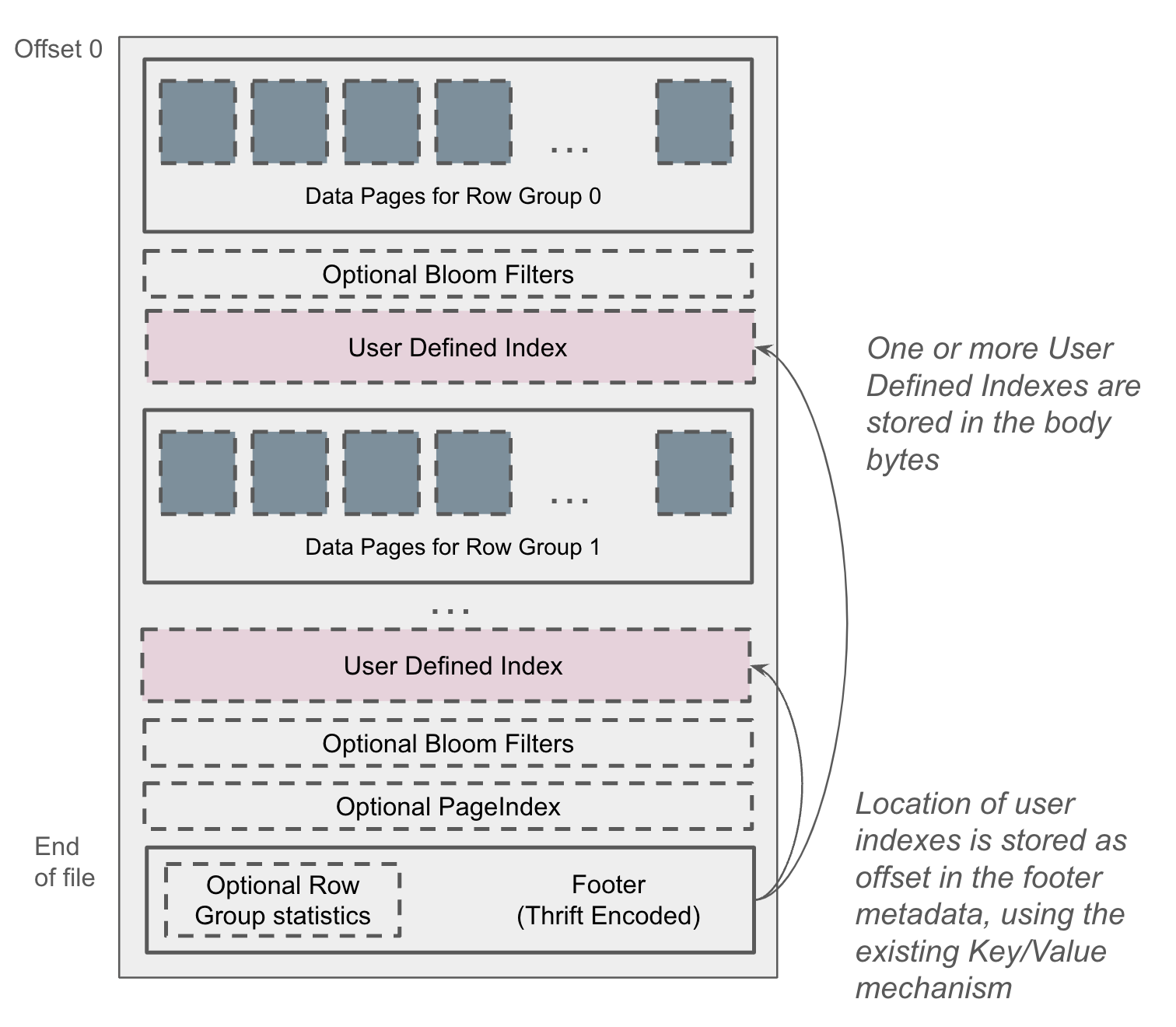
3. 嵌入用户自定义索引
- 嵌入原理: 将索引序列化为二进制格式并写入文件体,然后在页脚元数据中记录索引的位置。
- 灵活性: 用户自定义索引可以存储在文件体的任何位置,且可以应用于文件、行组、页甚至行级别。
- 示例: 嵌入一个简单的“唯一值索引”,用于文件级别的剪枝(跳过不包含目标值的文件)。
4. 示例:嵌入唯一值索引
实现步骤:
- 定义索引内容(如唯一值列表)。
- 将索引序列化为字节并写入文件体。
- 在页脚元数据中记录索引的偏移量。
- 扩展 DataFusion 的
TableProvider,使其能够读取并使用索引进行查询优化。
代码示例: 文章提供了详细的 Rust 代码示例,展示了如何序列化、写入和读取唯一值索引。
5. 兼容性验证
- 验证工具: 使用 DuckDB 读取包含自定义索引的 Parquet 文件,验证标准 Parquet 读取器会忽略未知的索引字节和元数据。
6. 结论
- 性能提升: 通过嵌入用户自定义索引,Parquet 系统可以在不破坏兼容性的情况下显著提升查询性能。
- 系统设计选择: 系统设计者可以根据具体需求在操作复杂性、性能、文件大小和成本之间进行权衡。
- 未来展望: 文章鼓励开发者探索在 Parquet 文件中使用自定义索引,而不是提出新的文件格式。
7. 关于 Apache DataFusion
- 简介: Apache DataFusion 是一个基于 Rust 的可扩展查询引擎工具包,使用 Apache Arrow 作为内存格式。
- 社区贡献: DataFusion 社区欢迎新贡献者加入,共同改进项目。
相关链接: - Apache Parquet - Apache DataFusion - Rust Parquet Library
评论总结
主要观点总结:
Parquet 文件格式的局限性及改进
- 评论1指出,Parquet 文件格式在扩展新元数据(如统计摘要、HyperLogLog 等)方面缺乏标准化方法,显示出其局限性。
- DataFusion 团队提出了一种巧妙的解决方案,通过在文件页脚和数据页之间插入任意数据,既保持了向后兼容性,又允许查询引擎(如 DataFusion)利用这些数据提升查询性能。
- 关键引用:
- "They have inserted arbitrary data between footer and data pages, which other readers will ignore. But query engines like DataFusion can exploit it."
- "他们通过在页脚和数据页之间插入任意数据,其他读取器会忽略这些数据,但像 DataFusion 这样的查询引擎可以利用它。"
改进的查询性能
- DataFusion 在 Parquet 文件中嵌入了一个新索引,用于存储列的所有唯一值,从而优化查询性能。例如,查询
WHERE nation = 'Singapore'可以利用该索引快速判断值是否存在,而无需扫描数据页。 - 关键引用:
- "They embed a new index to the .parquet file, and use that to improve query performance."
- "他们在 .parquet 文件中嵌入了一个新索引,并利用它来提升查询性能。"
- DataFusion 在 Parquet 文件中嵌入了一个新索引,用于存储列的所有唯一值,从而优化查询性能。例如,查询
技术方案的局限性
- 评论2质疑该技术是否仅限于 DataFusion,并询问是否有标准化可能,以便其他 Parquet 读取器也能利用该技术。
- 关键引用:
- "Cool, but this is very specific to DataFusion, no? Is there any chance this would be standardized so other Parquet readers could leverage the same technique?"
- "很酷,但这仅限于 DataFusion 吧?是否有标准化可能,以便其他 Parquet 读取器也能利用该技术?"
与 Iceberg 的 Puffin 文件的对比
- 评论3提到,Iceberg 的 Puffin 文件与 DataFusion 的技术有部分功能重叠,并提供了相关链接。
- 关键引用:
- "Note that there are 'Puffin files' associated with Iceberg which have some overlap with this functionality."
- "需要注意的是,Iceberg 的 'Puffin 文件' 与此功能有部分重叠。"
总结:
评论主要讨论了 Parquet 文件格式的局限性及 DataFusion 团队提出的改进方案,该方案通过嵌入新索引提升查询性能,但仅限于 DataFusion。同时,评论也提出了标准化可能,并对比了 Iceberg 的 Puffin 文件。