文章摘要
Gemini 2.5 Pro在目标检测任务中表现尚可,与2018年的Yolo V3在MS-COCO验证集上的性能相当。尽管多模态大语言模型在计算机视觉任务中不断进步,但尚未完全取代卷积神经网络(CNN)。作者通过一个小型基准测试评估了Gemini 2.5在MS-COCO数据集上的表现,结果显示其在目标检测方面有一定竞争力,但仍有提升空间。
文章总结
文章主要内容总结
标题: Gemini 2.5 在边界框检测方面表现如何?还行吧...
发布日期: 2025年7月10日
核心内容:
本文探讨了Gemini 2.5 Pro在目标检测任务中的表现,特别是在MS-COCO数据集上的表现。作者通过一个小型基准测试,将Gemini 2.5 Pro与2018年的Yolo V3进行了对比,发现其在目标检测任务中的表现与Yolo V3相当。
关键点:
背景:
多模态大语言模型(如Gemini)在计算机视觉任务中表现越来越出色,但作者质疑它们是否已经准备好取代传统的卷积神经网络(CNN)。为了验证这一点,作者在MS-COCO数据集上进行了目标检测测试。数据集:
使用了经典的MS-COCO数据集,该数据集包含80个类别,从“人”到“牙刷”不等。验证集包含5000张图像,用于测试Gemini的表现。测试方法:
作者设计了一个提示词(prompt),要求Gemini检测图像中的所有可见物体,并输出每个物体的标签、置信度、边界框和掩码。测试中使用了不同的模型版本(Pro、Flash、Flash-Lite)和不同的思考预算(think tokens)。结果:
- Pro模型表现最好,mAP(平均精度)约为0.34,与Yolo V3相当。
- Flash和Flash-Lite模型表现较差,尤其是Flash-Lite,mAP较低且错误率较高。
- 思考预算的增加显著降低了模型的表现。
- 非结构化输出在Flash和Flash-Lite上表现更好,但在Pro上表现较差。
图像对比:
文章展示了多张图像,对比了Gemini的预测边界框与真实边界框的差异。例如,Gemini在某些情况下能够检测到更多的物体,但在其他情况下可能会漏检或误检。
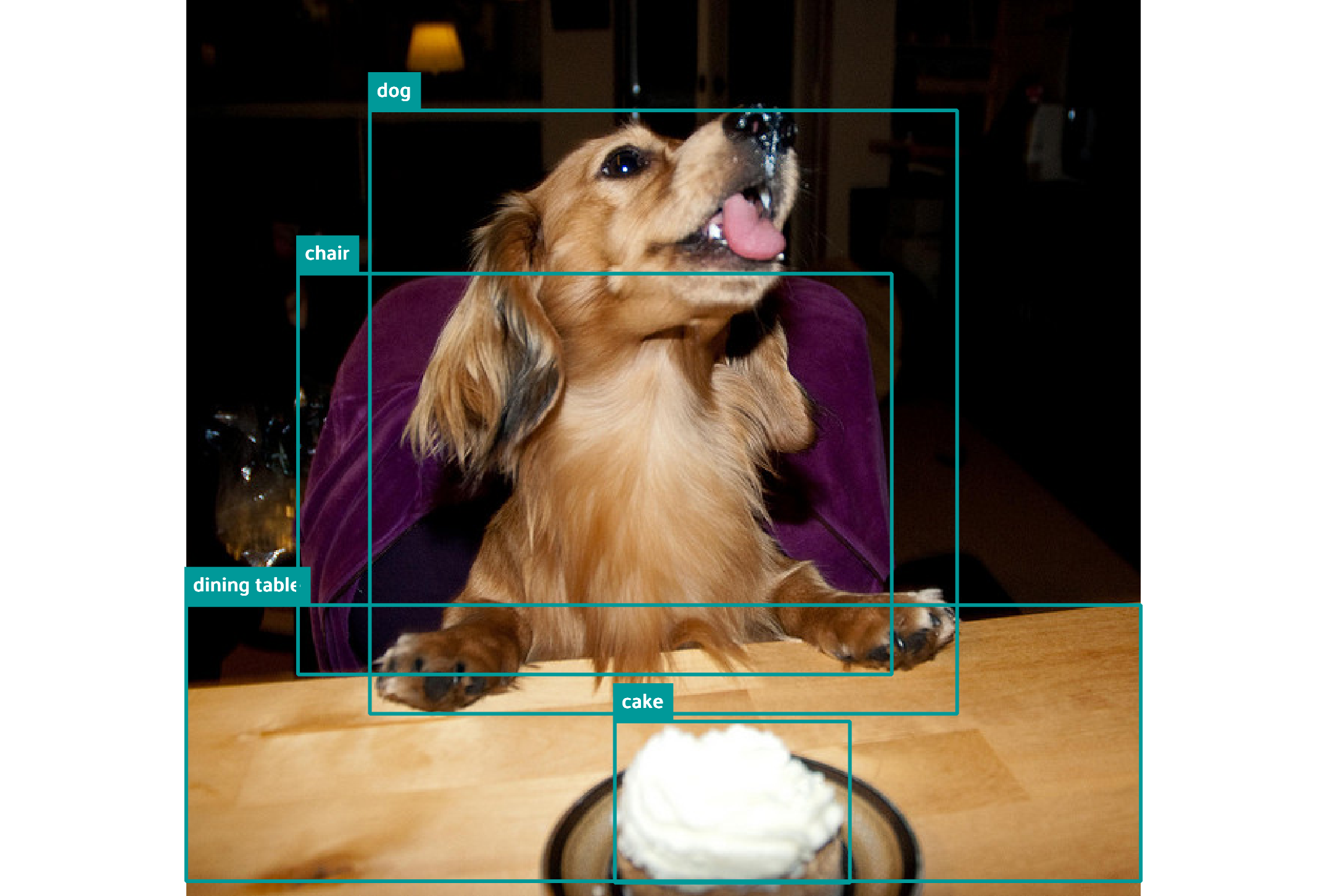
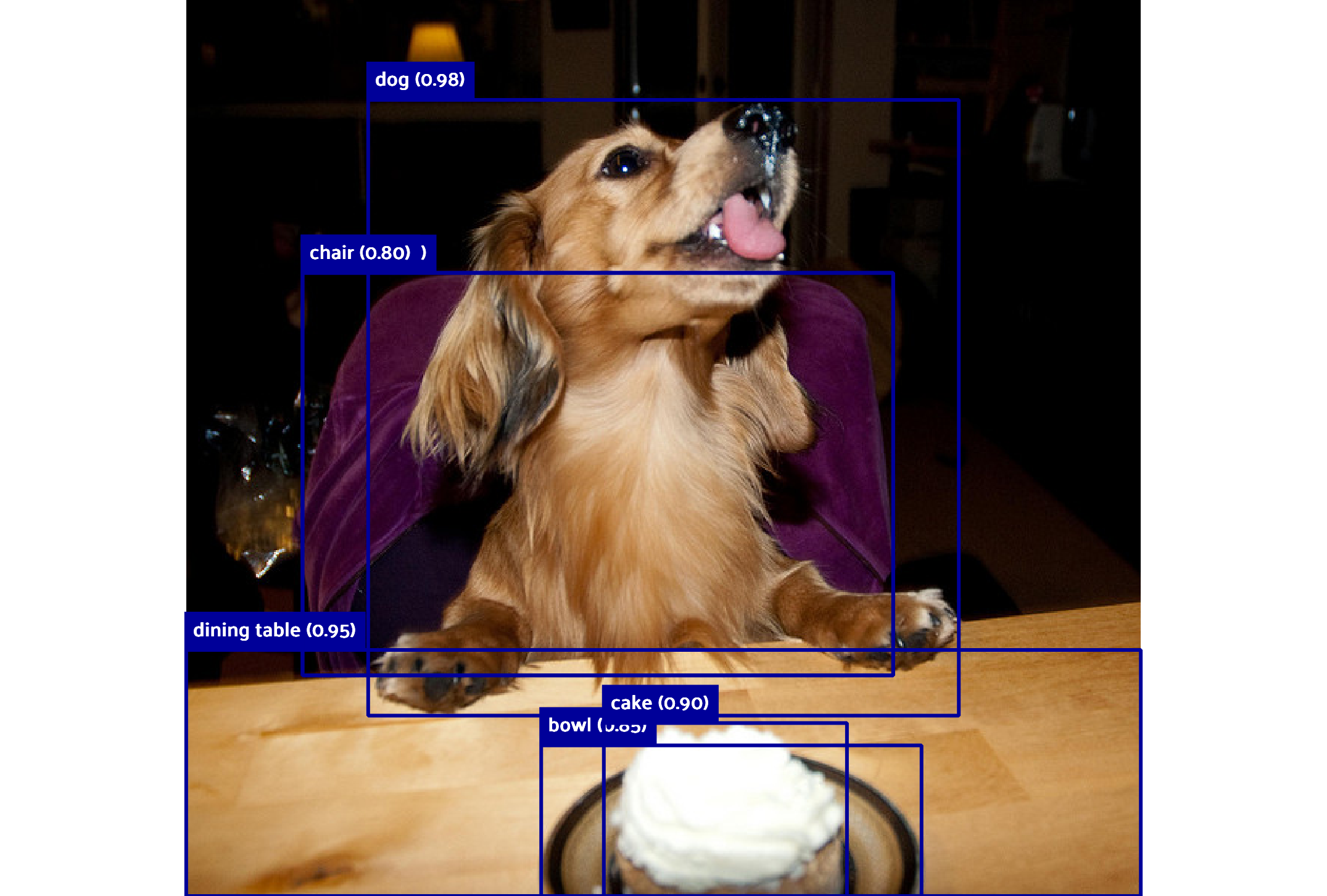
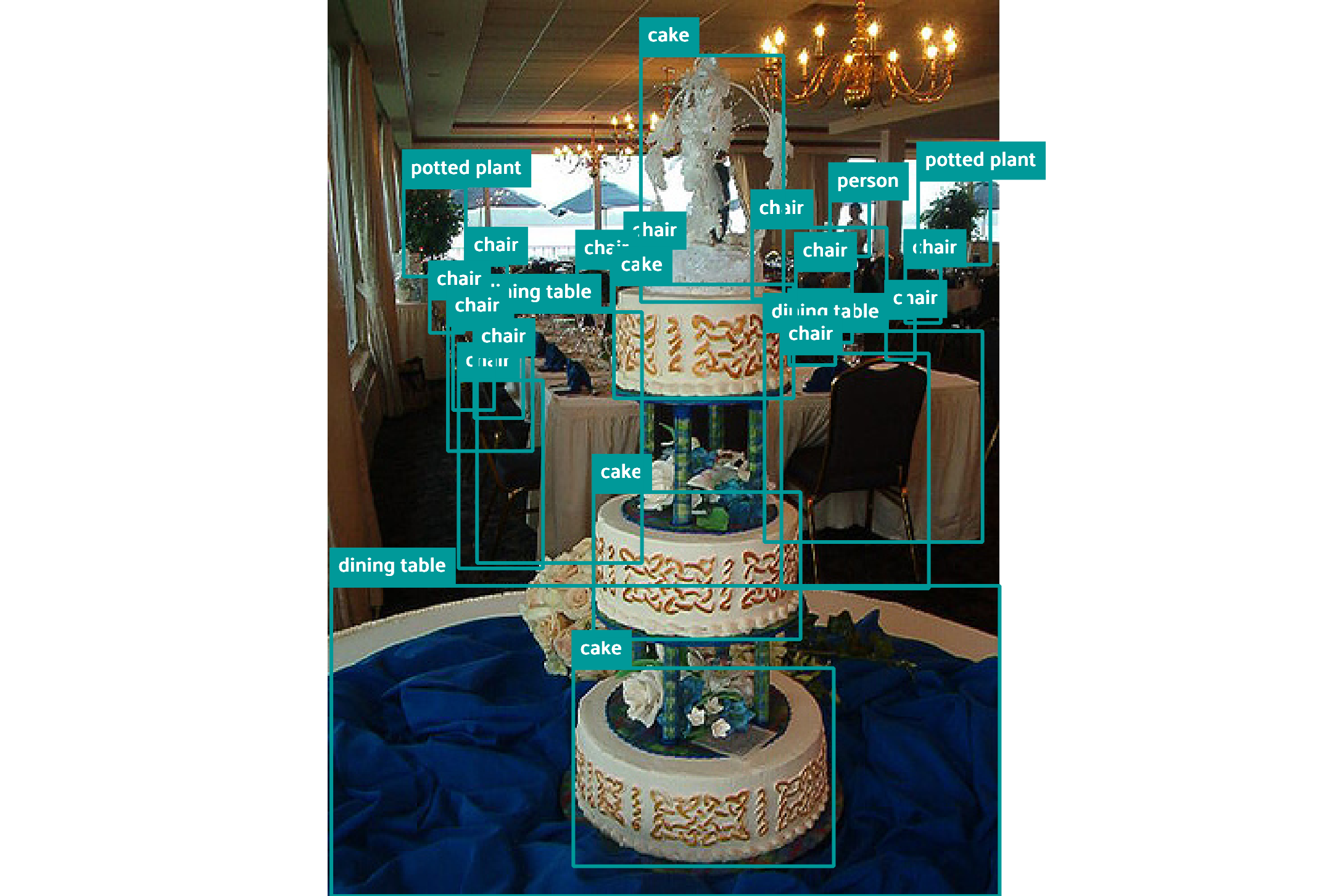


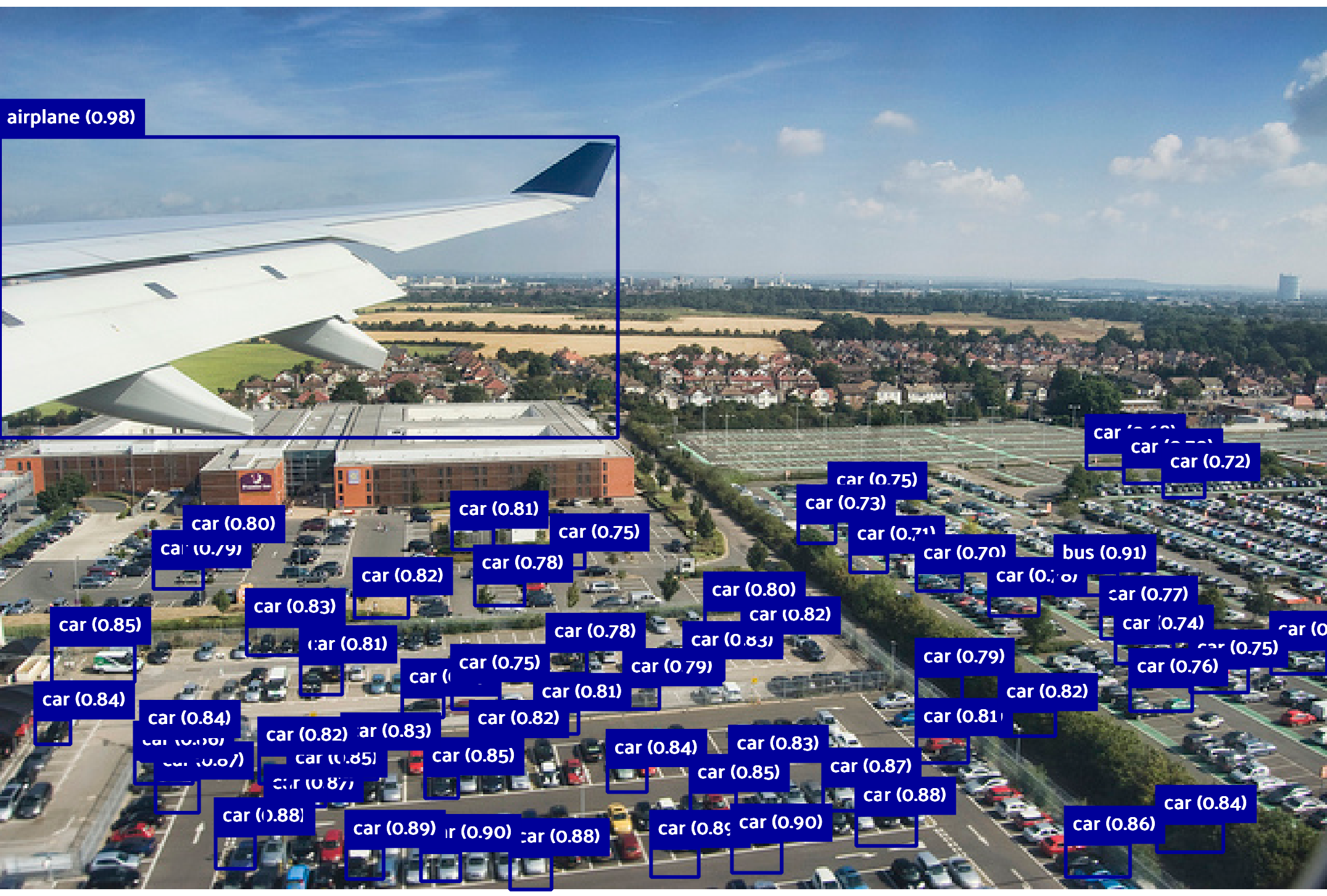
结论:
尽管Gemini 2.5 Pro在目标检测任务中表现不错,但CNN在速度、成本和可解释性方面仍然具有优势。然而,Gemini在开放集任务中的多功能性令人印象深刻,作者表示将在未来的项目中使用它。
参考文献:
文章还提到了Simon Willison的相关研究和一篇关于GPT-4o在视觉任务中表现的论文,供读者进一步了解。
总结:
Gemini 2.5 Pro在目标检测任务中表现良好,但与专门训练的CNN相比仍有差距。尽管如此,其在多任务处理中的灵活性使其成为一个有潜力的工具。
评论总结
主要观点总结:
边界框质量与数据集噪声处理
- EconomistFar 提到,边界框的小误差在边缘情况或数据有限时会迅速累积,询问如何处理噪声数据集中的边界框质量,是否依赖人工标注或数据增强。
- 引用:“Small inaccuracies can add up fast, especially in edge cases or when training on limited data.”
- bee_rider 提出,Gemini 的边界框标注可能作为自动标注工具,减少人工标注的繁琐。
- 引用:“maybe Gemini with it’s mediocre bounding boxes could be used as an infinitely un-bore-able annotater instead.”
- EconomistFar 提到,边界框的小误差在边缘情况或数据有限时会迅速累积,询问如何处理噪声数据集中的边界框质量,是否依赖人工标注或数据增强。
Gemini 在边界框检测中的表现与改进
- thegeomaster 指出,Google 模型(如 Gemini 2.0)经过专门的后训练,显著提升了边界框检测能力。
- 引用:“Google models >= Gemini 2.0 are all explicitly post-trained for this task of bounding box detection.”
- smus 提到,Gemini 2.5 在零样本检测中表现良好,但在提供额外视觉或文本上下文时性能下降。
- 引用:“performance degraded when provided visual examples to ground its detections from.”
- thegeomaster 指出,Google 模型(如 Gemini 2.0)经过专门的后训练,显著提升了边界框检测能力。
多模态 LLM 的应用潜力与局限性
- Alifatisk 认为多模态 LLM 是解决多种技术问题的“银弹”,涵盖文本分析、视频生成和边界框检测等领域。
- 引用:“Multimodal LLMs is our silver bullet to applying different technological solutions.”
- nolok 分享使用 Gemini 的经验,指出其在复杂任务中表现优异,但在简单计算中却频繁出错。
- 引用:“it kept trying to tally me totals, and there was always one wrong.”
- Alifatisk 认为多模态 LLM 是解决多种技术问题的“银弹”,涵盖文本分析、视频生成和边界框检测等领域。
边界框检测的技术细节与实验方法
- svat 提出多个关于边界框检测的技术问题,如坐标格式、归一化处理以及是否分多轮进行检测。
- 引用:“Do you ask for these coordinates as integer pixels or normalized between 0.0 and 1.0?”
- sly010 询问 LLM 如何执行非文本任务(如目标检测),质疑其是否与专用视觉模型共享能力。
- 引用:“How does an LLM do object detection? Or more generally, how does an LLM do anything that is not text?”
- svat 提出多个关于边界框检测的技术问题,如坐标格式、归一化处理以及是否分多轮进行检测。
Gemini 与其他技术的对比与结合
- aae42 讨论传统计算机视觉与多模态 LLM 的结合潜力,建议开发一个“超级视觉语言模型”以提高准确性。
- 引用:“why someone hasn’t made an ‘über vision language model’ that just exposes the old CV APIs as MCP or something.”
- aae42 讨论传统计算机视觉与多模态 LLM 的结合潜力,建议开发一个“超级视觉语言模型”以提高准确性。
总结:
评论主要围绕 Gemini 在边界框检测中的表现、多模态 LLM 的应用潜力及其局限性展开。Gemini 在零样本检测中表现优异,但在简单任务中可能出现错误。多模态 LLM 被认为具有广泛的应用前景,但其与传统计算机视觉技术的结合仍有待探索。技术细节如坐标格式、归一化处理等也引发了深入讨论。