文章摘要
大型语言模型的发展依赖于过去三十年在线文本的积累,但这些高质量数据资源正迅速消耗,可能在未来几年内耗尽。未来的AI进步将不再仅仅依赖参数堆叠,而是转向探索和获取有益经验的过程,关键在于收集对学习有帮助的特定经验,而非任何经验。
文章总结
文章总结
标题: 探索时代
主要内容:
背景与问题:
- 大型语言模型(LLMs)的发展依赖于过去三十年在线文本数据的积累,但这些数据资源是有限的。研究表明,按照当前的消耗速度,高质量英文文本可能在十年内耗尽。
- 当前的模型消耗数据的速度远快于人类生成数据的速度,这导致数据成为AI发展的瓶颈。
探索的重要性:
- David Silver和Richard Sutton提出“经验时代”,认为未来的AI进步将依赖于模型自身生成的数据。
- 文章进一步指出,瓶颈不在于获取任何经验,而在于获取对学习有益的经验。未来的AI进步将更依赖于探索,即获取新的、信息丰富的经验。
探索的成本:
- 探索的成本包括计算资源、合成数据生成、数据整理管道、人工监督等。文章将这些成本统一为“flops”(浮点运算次数),作为衡量资源消耗的抽象单位。
预训练与探索:
- 预训练阶段通过大量计算资源学习丰富的采样分布,为后续的强化学习(RL)提供了基础。预训练实际上支付了“探索税”,使得模型能够在探索阶段发现有效的解决方案。
- 小模型通过从大模型中蒸馏知识,继承了这种探索能力,从而提升了推理能力。
探索与泛化:
- 探索直接影响数据的多样性,而数据多样性是模型泛化能力的关键。在RL中,探索策略的改进可以显著提升模型在未见过的环境中的表现。
- 文章以Procgen基准测试为例,展示了更好的探索策略可以显著提升模型的泛化性能。
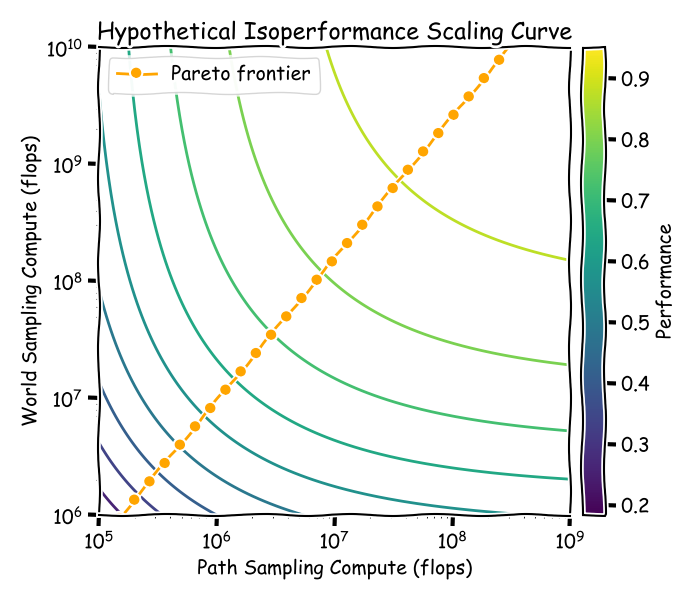
探索的两个维度:
- 世界采样: 决定在哪些环境中学习,包括数据收集、合成生成和整理。
- 路径采样: 决定在特定环境中如何收集数据,包括随机行走、好奇心驱动策略、树搜索等。
- 这两个维度形成了一个权衡曲线,资源需要在采样新环境和从单个环境中提取更多信息之间进行分配。
未来方向:
- 文章提出,未来的探索研究应关注如何在世界采样和路径采样之间找到最佳的资源配置方式,以实现更高的信息获取效率。
- 尽管目前还没有明确的探索目标,但通过设计更多的环境和更智能的路径采样策略,可以进一步提升模型的泛化能力。
结论:
- 现有的扩展范式虽然有效,但最终会饱和。未来的计算资源应投入到探索中,尽管目前还不清楚正确的扩展法则、环境生成器或探索目标,但直觉上这是可行的。
图片:
-  -
-  -
-  -
- 
致谢: - 感谢多位同事对文章的反馈和讨论。
评论总结
关于非笛卡尔显示器的探索
- 主要观点:webdevver提出,当前基于笛卡尔坐标系的显示器技术可能已经过时,建议探索非笛卡尔显示方式,如六边形或极坐标排列的像素,甚至模仿人类视觉传感器的有机排列方式。
- 关键引用:
- "pixels that are arranged in a hexagonal pattern. or pixels arranged in a radial pattern and addressed via polar coordinates."
(“像素可以按六边形或极坐标排列。”) - "all this bitmap x/y display stuff is very pre-AI-ish. old tech. victorian era clockwork mechanism."
(“这些基于位图x/y的显示技术非常前AI时代,是老技术,像维多利亚时代的机械装置。”)
- "pixels that are arranged in a hexagonal pattern. or pixels arranged in a radial pattern and addressed via polar coordinates."
智能作为过程而非实体
- 主要观点:visarga认为智能不应被视为名词,而是一个基于探索和学习的过程,类似于河流与河岸的相互塑造关系。模型和活动本身都不具备智能,智能源于它们的共同作用。
- 关键引用:
- "It is a process, a search process based on exploration and learning."
(“它是一个过程,一个基于探索和学习的搜索过程。”) - "Intelligence comes from their co-constitutive relation."
(“智能源于它们的共同构成关系。”)
- "It is a process, a search process based on exploration and learning."
版权与探索的争议
- 主要观点:dangus对“探索”一词提出质疑,认为其可能掩盖了版权侵权问题,并预测随着法律诉讼的增加,免费获取的文本、视频和音频内容将减少,未来可能会出现类似robots.txt的机制来保护内容不被用于训练。
- 关键引用:
- "“Exploration” is a funny word for “copyright infringement.”"
(“‘探索’是对‘版权侵权’的委婉说法。”) - "I think it’s entirely fair that there should be a robots.txt type of mechanism for sites to opt out of being crawled for training."
(“我认为应该有一种类似robots.txt的机制,让网站可以选择不被抓取用于训练。”)
- "“Exploration” is a funny word for “copyright infringement.”"
无关评论
- dodomodo的评论仅提到一条推文,未提供实质性观点。